Attribution Patching: Activation Patching At Industrial Scale
The following is a write-up of an (incomplete) project I worked on while at Anthropic, and a significant amount of the credit goes to the then team, Chris Olah, Catherine Olsson, Nelson Elhage & Tristan Hume. I've since cleaned up this project in my personal time and personal capacity.
TLDR
- Activation patching is an existing technique for identifying which model activations are most important for determining model behaviour between two similar prompts that differ in a key detail
- I introduce a technique called attribution patching, which uses gradients to take a linear approximation to activation patching. (Note the very similar but different names)
- This is way faster, since activation patching requires a separate forward pass per activation patched, while every attribution patch can be done simulataneously in two forward and one backward pass
- Attribution patching makes activation patching much more scalable to large models, and can serve as a useful heuristic to find the interesting activations to patch. It serves as a useful but flawed exploratory technique to generate hypotheses to feed into more rigorous techniques.
- In practice, the approximation is a decent approximation when patching in "small" activations like head outputs, and bad when patching in "big" activations like a residual stream.
Introduction
Note: I've tried to make this post accessible and to convey intuitions, but it's a pretty technical post and likely only of interest if you care about mech interp and know what activation patching/causal tracing is
Activation patching (aka causal tracing) is one of my favourite innovations in mechanistic interpretability techniques. The beauty of it is by letting you set up a careful counterfactual between a clean input and a corrupted input (ideally the same apart from some key detail), and by patching in specific activations from the clean run to the corrupted run, we find which activations are sufficient to flip things from the corrupted answer to the clean answer. This is a targeted, causal intervention that can give you strong evidence about which parts of the model do represent the concept in question - if a single activation is sufficient to change the entire model output, that's pretty strong evidence it matters! And you can just iterate over every activation you care about to get some insight into what's going on.
In practice, it and it's variants have gotten pretty impressive results. But one practical problem with activation patching + iterating over every activation is the running costs - every data point in activation patching requires a single forward pass. This is pretty OK when working with small models or with fairly coarse patches (eg an entire residual stream at a single position), but it gets impractical fast if you want very fine-grained patches (eg between each pair of heads, specific neurons, etc) or want to work with large models.
This post introduces attribution patching, a technique that uses gradient-based approximation to approximate activation patching (note the very similar but different name!). Attribution patching allows you to do every single patch you might want between a clean and corrupted input on two forward passes and one backward pass (that is, every single patch can be calculated by solely caching results from the same 3 runs!). The key idea is to assume that the corrupted run is a locally linear function of its activations (keeping parameters fixed!), take the gradient of the patch metric with respect to each activation, and consider a patch of activation x to be applying the difference corrupted_x -> corrupted_x + (clean_x - corrupted_x), with patch metric change (corrupted_grad_x * (clean_x - corrupted_x)).sum().
This post fleshes out the idea, and discusses whether it makes any sense. There is an accompanying notebook with code implementing attribution patching for the IOI circuit in GPT-2 Small and comparing it to activation patching in practice - if you prefer reading code, I endorse skipping this post and reading the notebook first.
The intended spirit of this post is to present an interesting technique, arguments for or against why it would work, intuitions for where it would work well, an implementation to play around with yourself, and some empirical data. My argument is that attribution patching is a useful tool for exploratory analysis, narrowing down hypotheses, and figuring out the outlines of a circuit, and that it's a useful part of a mech interp toolkit. I do not want to argue that this is stictly better than activation patching, nor that it's perfectly reliable, and I think the most valuable use cases will be to generate hypotheses that are then explored with more rigorous techniques like causal scrubbing
Ideally I'd have much more empirical data to show, and I may follow up at some point, but I wanted to get something out to share the idea. I am not arguing that attribution patching is the only technique you need, that it's flawless, that all of my arguments and intuitions are correct, etc. But I think it's a useful thing to have in your toolkit!
Contents
This post is long and wide-ranging, and I expect different parts will be of interest to different readers:
- A recap of activation patching: Skip if you're familiar
- Attribution patching: The main original contribution of this post
- The key idea
- Motivation for why this is a massive speed up over activation patching, and why to care
- Empirical results
- Conceptual framework: I expect this to be of interest even if you're skeptical of attribution patching
- Patching Variants: A wide ranging discussion on different variants of patching, existing work, and my vision for exciting directions
- Preliminary results applying attribution patching to path patching
- Attention pattern attribution - a non-patching tool for better understanding attention patterns on any single prompt
- Future work, related work, and conclusion
Activation Patching Recap
*The point of this section is to give the gist + some context on activation patching. If you want a proper tutorial, check out my explainer and the relevant code in exploratory analysis demo. I dig deeper into the foundational intuitions in a later section
The core idea is to set up a careful counterfactual between a clean prompt and a corrupted prompt, where the two differ in one key detail. We set up a metric to capture the difference in this key detail. The model is then run on the corrupted prompt, and a single activation is then patched in from the clean prompt, and we check how much it has flipped the output from the corrupted output to the clean output. This activation can be as coarse or fine grained as we want, from the entire residual stream across all layers at a single position to a specific neuron at a specific layer and specific position.
In-Depth Example
Let's consider the example of residual stream patching for the Indirect Object Identification task. The IOI circuit, for reference:
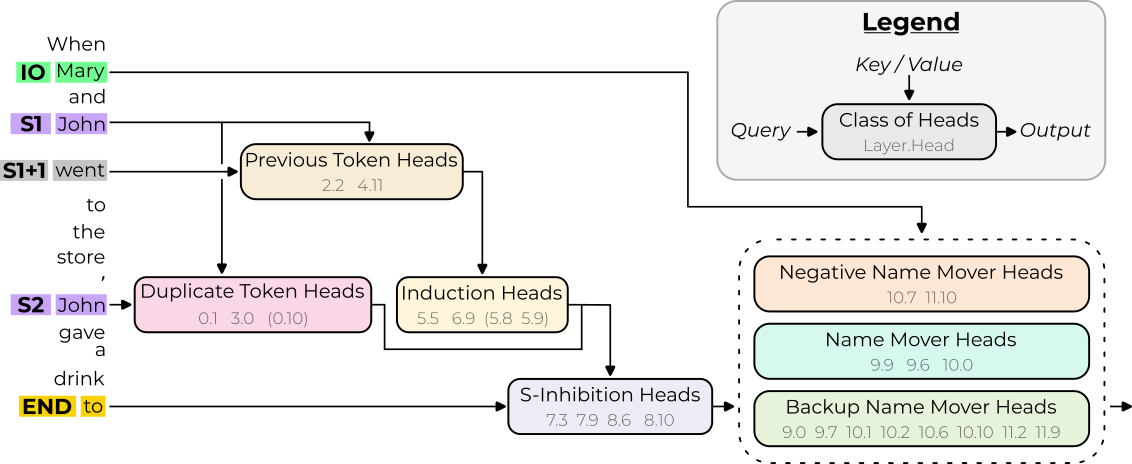
(Aside) Context + Details on the example
Adapted from Interpretability in the Wild - see my explainer for more on this circuit. See code for (something like) this example at Exploratory Analysis Demo
We want to reverse-engineer how GPT-2 Small does indirect object identification, and in particular analyse the residual stream at different positions to see how the information about which name is the indirect object flows through the network. We focus on the clean prompt "When John and Mary went to the store, John gave the bag to" and how it is mapped to the clean answer " Mary". We take our corrupted prompt as "When John and Mary went to the store, Mary gave the bag to" and the corrupted answer " John" and our patching metric is the logit difference final_logit[token=" Mary"] - final_logit[token=" John"].
We run the model on the clean prompt and cache all activations (the clean activations). We do this by residual stream patching - for a specific layer L and position P, we run the model on the corrupted prompt. Up until layer L it's unchanged, then at layer L we patch the clean residual stream in at position P and replace the original residual stream. The run then continues as normal, and we look at the patch metric (logit difference). We iterate over all layers L and positions P. (at layer L we patch at the start of each layer's residual stream, ie layer L patch does not include any outputs of attn or MLP layer L)
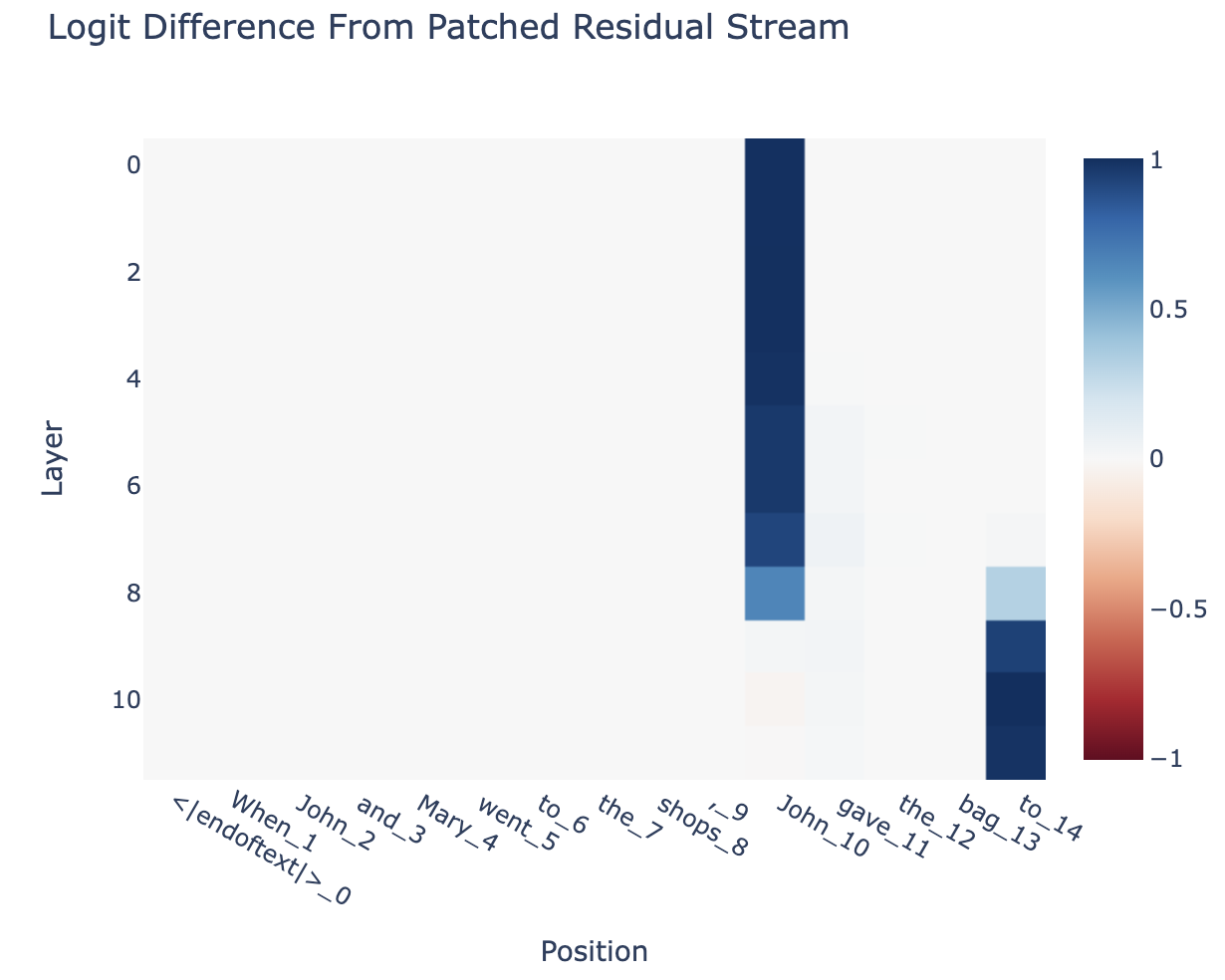
Analysis of Example
We see that early on (top) things are at the second subject (S2, value " John") token, there's some transition at layers 7 and 8 (which we now know is from the S-Inhibition Heads), and then things move to the final token
We are tracking how information of "which name is the second subject" flows through the network, not what computation is done with that information. This is an important difference!
For example, we know that the duplicate token heads operate on the S2 token to identify whether or not it's duplicated. And then this feature is moved to the final token via the S-Inhibition heads (in layers 7 & 8, as predicted). But the circuit could involve eg a "subject mover" head in layers 7 & 8 that move the value of S2 to the final token, and then eg the model copies all prior names except for names equal to the value of the copied subject, so the duplication analysis is done there. This is equally valid!
A key observation is that we are patching a single activation from clean to corrupted. This means we're checking which activations are sufficient to contain the key information to reconstruct the clean solution. This is very different from checking which activations matter, or from patching in specific corrupted activations into the clean run to see which most break things (essentially a form of ablation). IMO being sufficient is much stronger evidence than just mattering, but I think both can give valuable info.
(Aside) A braindump of further observations worth making from this example
- Our observations are not very surprising - this is obviously the case before layer 0 (the second subject token is the only difference) and after the final layer (we read off from the logits at the final position). The interesting thing is that they do not route via any intermediate tokens, that it remains pretty sparse and sharp throughout and that there's a fairly sharp transition during layers 7 and 8
- All tokens before the second subject are unchanged, so they obviously don't matter
- We did not learn anything about how the model identifies eg that it's doing indirect object identification, looking for names, the next token begins with a space, etc. This is by design! We compared two prompts that only differed in the identity of the indirect object but kept all other contexts the same.
- We could try to design clean and corrupted prompts to isolate out some of these other facts to investigate.
- Notably, the position of John and Mary (in the first clause) remains the same, but the position and value of the indirect object change. Some of the IOI circuit tracks position of the indirect object, but we don't notice the difference. We might find this by patching from
"When Mary and John went to the store, John gave the bag to" - We could also try patching from a totally different corrupted prompt, eg iid random tokens or having the second subject be a third name (ABC distribution) or arbitrary sentences from openwebtext, etc.
- This would also let us track some of the above questions around whether it's a name, doing IOI at all, etc, but has some complexities, as we'll discuss later.
- The metric of logit difference between John and Mary also controls for the parts of the model identifying names, to do IOI, etc. Those circuits should favour John and Mary equally and cancel out.
- Logit difference is great because it's equal to the difference in log prob but also a linear-ish function of the final residual stream and so is neater to analyse.
- There's a bunch of exposure to specific random noise here from our single prompt pair.
- This can get significantly cleaner if we also flip the prompts around, and have our clean prompt as corrupted and vice versa. This is a nice symmetry of the IOI task, and I try to do this where possible.
- For example, " John" is a more common token than " Mary". In fact, the folded layer norm bias boosts the John logit by about 1 relative to the Mary logit, 1/3 of the total logit difference of 3! But this fixed bias cancels out if we average over pairs of prompts.
- Also, just having more prompts! In the exploratory analysis demo notebook I have 4 pairs of pairs (8 total), but ideally you'd have way more to smooth out this noise and figure out what's up with the circuit.
- This can get significantly cleaner if we also flip the prompts around, and have our clean prompt as corrupted and vice versa. This is a nice symmetry of the IOI task, and I try to do this where possible.
What Is Attribution Patching?
The key motivation behind attribution patching is to think of activation patching as a local change. We isolate a specific activation, and patch in a clean version, altered by a specific change in the input. If done right, this should be a pretty small change in the model, and plausibly in the activation too! The argument is then that, given that we're making a small, local change, we should get about the same results if apply this small change to a linear approximation of the model, on the corrupted prompt!
Intuitively, attribution patching takes a linear approximation to the model at the corrupted prompt, and calculates the effect of the local change of the patch for a single activation from corrupted to clean at that prompt.
To compute this, we take a backwards pass on the corrupted prompt with respect to the patching metric, and cache all gradients with respect to the activations. Importantly, we are doing a weird thing, and not just taking the gradients with respect to parameters! Then, for a given activation we can compute ((clean_act - corrupted_act) * corrupted_grad_act).sum(), where we do elementwise multiplication and then sum over the relevant dimensions. Every single patch can be computed after caching activations from two forward passes and one backwards pass.
Formally, the technique of attribution patching is as follows:
(Aside) Overly mathematical operationalisation of attribution patching
- Notation: We start with a model $M: \mathcal{I} \to \mathcal{L}$, a clean input $C$, a corrupted input $R$, a specific activation $A: \mathcal{I} \to \mathcal{A}$ and a metric $P: \mathcal{L} \to \mathbb{R}$.
- We define three relevant spaces, $\mathcal{L}:= \textrm{Logits}$, $\mathcal{A}:= \textrm{Values of Activation }A$ (which is equivalent to $\mathbb{R}^n$, with the $n$ depending on $A$) and $\mathcal{I}:= \textrm{Inputs}$ the space of possible prompts
- We define a patched model as a function $M_A: \mathcal{I} \times \mathcal{A} \to \mathcal{L}$.
- Note that $A$ denotes the abstract notion of the activation (eg "residual stream at layer 7 and position 3") and we will use $a$ to denote a specific instantiation of this value (eg "the 768 dimensional vector giving the residual stream at layer 7 and position 3 on the input
"Hello, my name is Neel")
- Activation patching is when we take $a := A(C)$ and output $m = P(M_A(R; a)) = P(M_A(R; A(C)$
- We can think of this as a function $M_{P}(C; R; A) = P(M_A(R; A(C)))$, from $\mathcal{I} \times \mathcal{I} \times \textrm{Possible Activations} \to \mathbb{R}$
- In practice, activation patching looks like holding $C$ and $R$ fixed and varying $A$ over the (discrete!) set of possible activations in the model. Notably, we vary which activation is patched (eg residual stream at layer 7 vs residual stream at layer 8), we do not vary things in the space of activation values $\mathcal{A}$ (eg which value the residual stream at layer 7 takes on)
- Attribution patching is when we take a local linear approximation to $ f_A(I, a) = P(M_A(I; a)): \mathcal{I} \times \mathcal{A} \to \mathbb{R}$, the function mapping an input and patched activation to the metric on their logits. We start at the metric's value on the unpatched corrupted input, $f(R; A(R)) = P(M_A(R; A(R))) = P(M(R))$, and then vary $a$ from $A(R)$ to $A(C)$.
- To do this, we take the derivative of $f_A$. Importantly, we differentiate with respect to the activation $a \in \mathcal{A}$, while holding the input fixed!
- Recall that $\mathcal(A)$ is just $\mathbb{R}^n$ for some $n$ (the number of elements in the activation $A$)
- Some activations are tensors, eg a residual stream across all positions is a
[d_model, position]tensor, but we can flatten it to an = d_model * positionvector, and think of it like that.
- Some activations are tensors, eg a residual stream across all positions is a
- So taking the derivative with respect to $a$ at value $a=b$ is basic multivariate calculus, and gives us the directional derivative $\frac{\partial f_A}{\partial a}|_{a=b} \in \mathbb{R}^n$
- Recall that $\mathcal(A)$ is just $\mathbb{R}^n$ for some $n$ (the number of elements in the activation $A$)
- $f(R; A(C)) - f(R; A(R)) \approx (A(C) - A(R) ) \cdot \frac{\partial f_A}{\partial a}|_{a=A(R)}
- Where $A(C), A(R), \frac{\partial f_A}{\partial a}|_{a=A(R)} \in \mathbb{R}^n$.
- Importantly, as we vary the activation $A$ (again, in the discrete set of different activations in the model, not the space of values of a single activation), we're still taking derivatives to the same start point $f(M(R))$. We can think of $M$ as being a function of every potentially-patchable activation and take the partial derivative with respect to each of them. This is what back propogation does, and so we calculate every
- Late activations depend on early ones, which makes it somewhat messy, but partial derivatives make this the right abstraction (I think)
- To do this, we take the derivative of $f_A$. Importantly, we differentiate with respect to the activation $a \in \mathcal{A}$, while holding the input fixed!
Why Care?
The main reason I think you should care about this is that attribution patching is really fast and scalable! Once you do a clean forward pass, corrupted forward pass, and corrupted backward pass, the attribution patch for any activation is just ((clean_act - corrupted_act) * corrupted_grad_act).sum(). This is just elementwise multiplication, subtraction, and summing over some axes, no matmuls required! And is all very straightforwards to code in my TransformerLens library, see the attached notebook. While activation patching needs a forward pass per data point. This makes it easy to do very fine-grained patching, eg of specific neurons at specific positions, which would be prohibitively expensive otherwise.
(Aside) Estimate of the asymptotic runtime of attribution patching vs activation patching
For a model with $N$ layers, d_model $M$, d_mlp $4M$, d_head $6$, $\frac{M}{64}$ heads and prompt length $P$ (fairly standard hyper-params): the number of parameters is $O(NM^2)$, the runtime of a forward pass is $O(NM^2P + NMP^2)$ (matmuls and attention respectively), and a backwards pass is about 2x as expensive as a forwards pass, and there are $\frac{MN}{64}$ heads and $4MN$ neurons.
So if a forward pass takes computation $C$, if we want to do a patch for each head at each position, we get things taking $\frac{MN}{64} PC$ vs $4C$ ish (the attribution patching computation is linear in the size of the activations, so is negligible compared to $C$, it's $O(PMN)$). For GPT-2 XL this is $M=1600,N=48$, so for a prompt of length $P=100$ tokens this is a $30,000$x speedup
It's easy to give a somewhat unfair comparison - there's a lot of heuristics you could use to do activation patching more intelligently, eg patching in a head across all positions and only splitting the important ones by position, ditto for layers and splitting into heads, etc. But I think the overall point stands! It's nice to be able to do fine-grained activation patching, and attributing patching is a very fast approximation. Further, we can decompose even further and eg do efficient direct path patching (described later) between all pairs of components, like each attention head's output and the Q, K and V input of each attention head in subsequent layers.
Further, linearity is an incredibly nice property! This makes the technique easy to code, reason about, and to build upon. You can break any component down into sub-components, and that components attribution is the sum of the attribution of its sub-components - an MLP layer breaks down into the sum across specific neurons, an attention layer breaks down into the sum of heads, the attribution of anything across all positions is the sum of per-position attributions, etc. Intuitively, this is because linearity is additive, and because it lets us think of each possible change independently (so long as those changes happen in the same layer - the attribution of all heads in attn layer 7 is the sum of each head's, but this does not work for a head in layer 7 and head in layer 8).
Notably, there are two ways to decompose an activation - by dividing its elements up (eg breaking down an attention head's output over all positions into its output per position) and by breaking it down into the sum of activations of the same shape, eg breaking the residual stream down into the sum of each component's output. This latter idea has the exciting consequence that you can easily do direct attribution path patching for any pair of components (eg all pairs of attention heads).
As a note on framing, I see this foremost as an exploratory, hypothesis-generating technique, not a confirmatory technique (see my breakdown of thinking about mech interp techniques for more). I think it's a useful and very fast + scalable technique, that can rapidly teach you things about a network and its circuits and narrow down the hypothesis space, which you can then try to verify with more involved and rigorous techniques like causal scrubbing. Or even just find the top N attribution patches, and then check these with actual activation patching, and just use this as a heuristic search. Within this framing, it matters way more if the technique gives us false negatives (important components seem to not matter) than if it gives false positives (unimportant components seem important) or just introduces error in how important each component seems. A core part of my argument below is not that attribution patching always works, but rather that it mostly breaks in the contexts where activation patching also breaks.
Further, I think it's mostly an innovation on the scattershot approach of "do activation patching on everything to see what matters and what doesn't", as an intitial step in localising a circuit. There's a bunch of more targeted approaches with patching, in particular patching in several key activations at once to study how they compose, that attribution patching is badly suited for. In particular, as discussed later, attribution patching assumes linearity, and studies the effect of each patched feature holding everything else fixed, and a key advantage of patching many components at once is the ability to track the interaction between them.
Intuitions for Attribution Patching
When I first started working on this, attribution patching felt pretty confusing and hard to get my head around, but I now find it very easy to reason about, so I want to dwell briefly on the right mindset.
The core intuition is that it's a linear approximations. Linear approximations, importantly, imagine varying each scalar activation while holding everything else fixed and looking at the effect on the patching metric. Where scalar activation generally means eg a residual stream element in the standard basis, an attention pattern weight, an element of a head's value vector in the standard basis, etc (though is meaningful in other bases too). Holding everything else fixed, we can think of the model as a function from $\mathbb{R}\to\mathbb{R}$ that's differentiable. clean_act_scalar - corrupted_act_scalar here is just the distance that we move along the x axis, and corrupted_grad_act_scalar is the slope at corrupted_act_scalar, so the attribution formula (clean_act_scalar - corrupted_act_scalar) * corrupted_act_scalar immediately falls out.
We don't normally care about a single residual stream element, but because linearity lets us treat everything independently and additively, the overall effect of a head's output's attribution patch is the sum of the patch effect for each scalar element of that head's output. This exactly gives us the elementwise product then sum over the relevant axes formula from before!
Further, every component's attribution can be broken down into the things that make it up. There's two ways to do this:
- Partitioning the elements of an activation: Eg The total attribution of a head across all positions is the sum of its per position attribution, because in the first case we take the
[batch, pos, d_model]tensor of the head's output and sum over all dimensions, in the second we don't sum over the pos dimension! - Linearly decomposing an activation into a sum of other activations: Eg The total attribution of an attention layer's output is the sum of the attribution of each head's output.
These two come up all over the place! In practice, the way I compute attribution patches is by computing a big AttributionCache object, which is basically a dictionary mapping each activation's name to (clean_act - corrupted_act) * corrupted_grad_act. To get the attribution patch for any specific activation, we then just reduce over the relevant axes.
Does This Work In Practice? (Experiments)
The main evidence I want to present here is the attached notebook, where I implement attribution patching, and run it in a bunch of increasingly fine-grained ways on the IOI circuit. The TLDR is that it's a bad approximation for "big" activations like residual stream patching and for MLP0, a good approximation for all other layer outputs, head outputs, and more zoomed in head activations (queries, keys, values, attention patterns), and lets us recover the broad strokes of the IOI circuit. In the next section I dig more into the theory and intuitions of where it should work and why.
Big activations
Per block activations, residual stream, attention layer output and MLP layer output, as a scatter plot of activation vs attribution:

It works badly for residual streams and MLP0, well for everything else. Intuitively, because attribution patching is a linear approximation it will work best for small changes. Here, LayerNorm makes small a question of relative size to the rest of the residual stream, so it makes sense that a full stream or early layer outputs work badly.
It's interesting to look qualitatively at the residual stream - despite the terrible approximation, you can still kind of get the gist of what's going on.
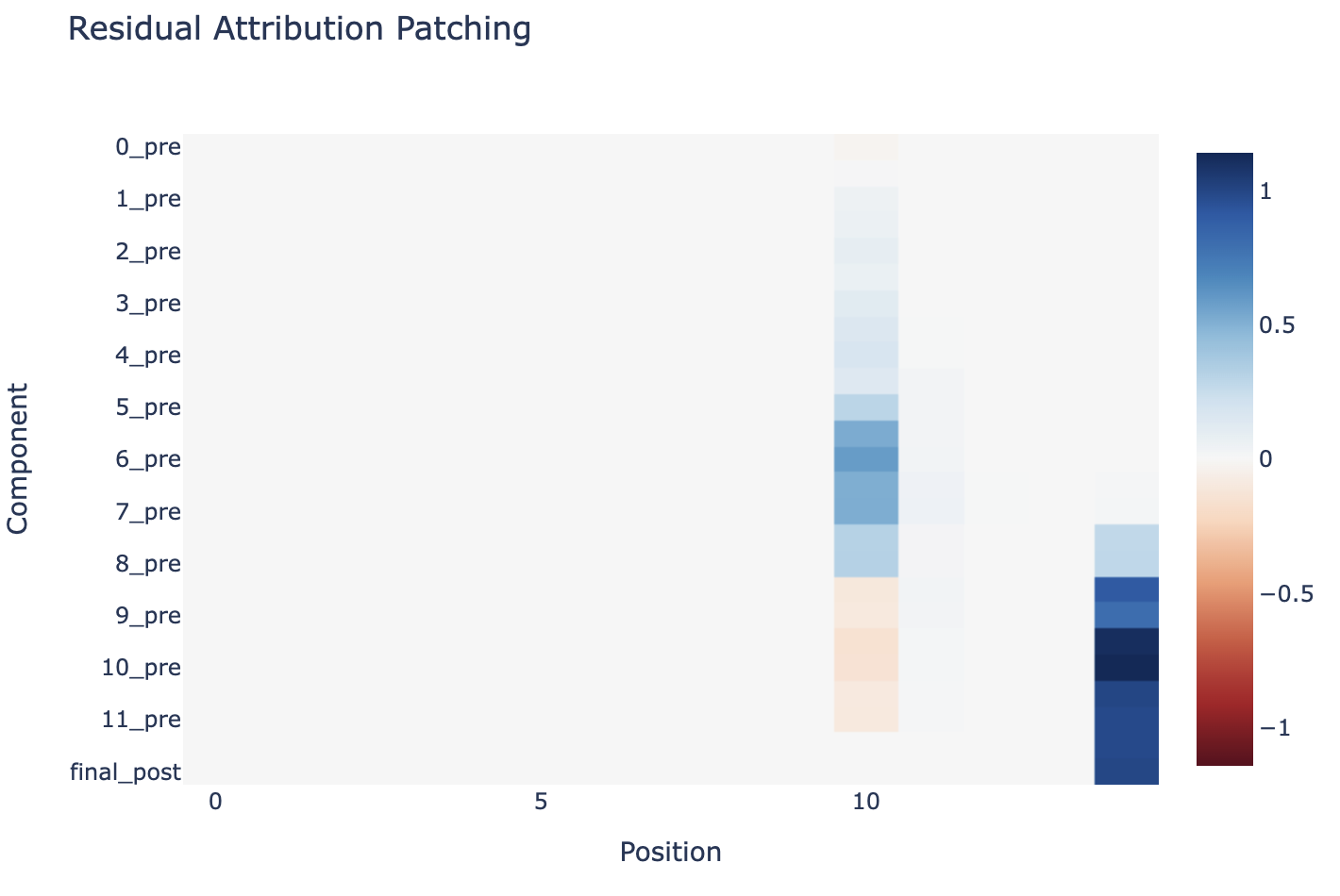
As I discuss later, LayerNorm makes the residual stream particularly messy. And as far as I can tell in GPT-2 Small, MLP0 acts significantly as an extended embedding used to break the symmetry between the tied embedding and unembedding (ie later layers look at MLP0 when they'd normally look at the token embeddings), so it makes sense that MLP0 is particularly bad - the embeddings presumably have more of a discrete than continuous structure (since there's only 50,000 possible token values), so a linear approximation seems unlikely to work there.
Zooming in on Heads
The IOI circuit is about specific attention heads and how they connect up, so patching on heads on specific positions, and sub parts of heads (queries, keys, values, attention pattern).
Patching Head outputs, queries, keys, values and patterns as a scatter plot (for each heads across all positions, comparing activation and attribution patching)
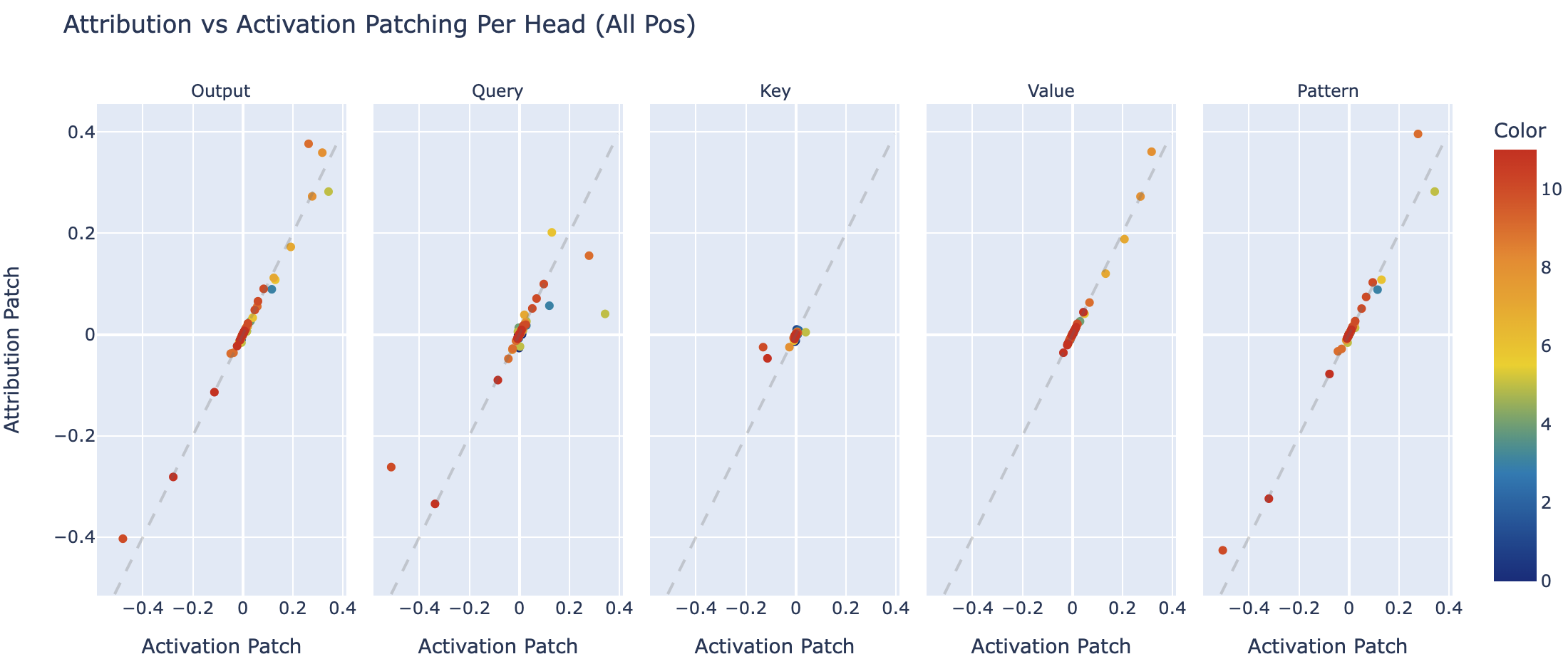
We can also make this graph with a per position patch (so a separate value for each layer, head and position), and we see much the same results. This isn't very surprising since every head predominantly acts at one source and one destination position.
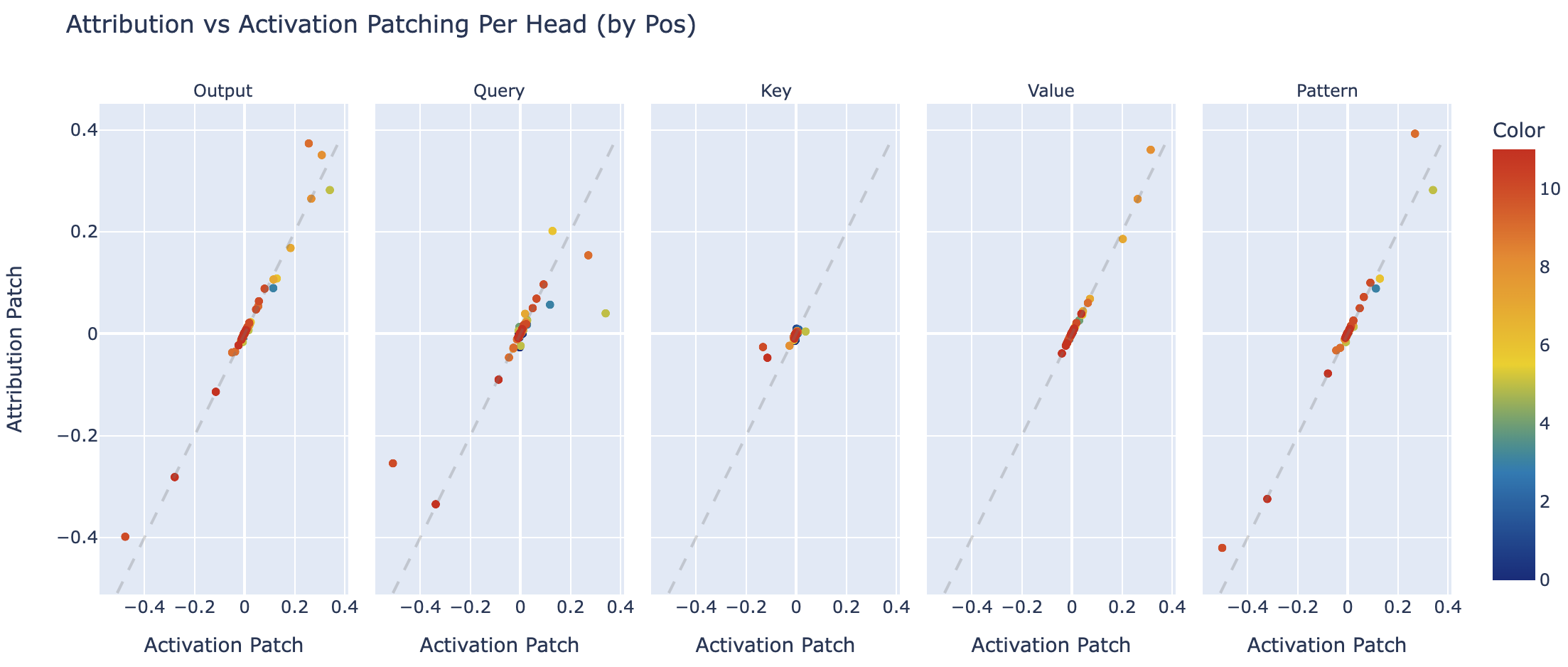
In my Exploratory Analysis Demo I go through how activation patching can re-derive much of the IOI circuit, so this is a good validation of attribution patching being useful!
Comparing ranks
While patching does return a continuous metric, one way to use it in practice is just to use it as a heuristic to take the top K activations that matter (either by absolute value, or taking the top positive ones, since some are very negative, like negative name movers!). In this framing, all that matters is the order of the activations on the patched metric, so how does this hold up?
In the diagram below, I take a scatter plot comparing the heads, this time patched across all positions, on their overall output, pattern, query, key or value (as separate plots). They're coloured by the activation patch value for that head + activation type.
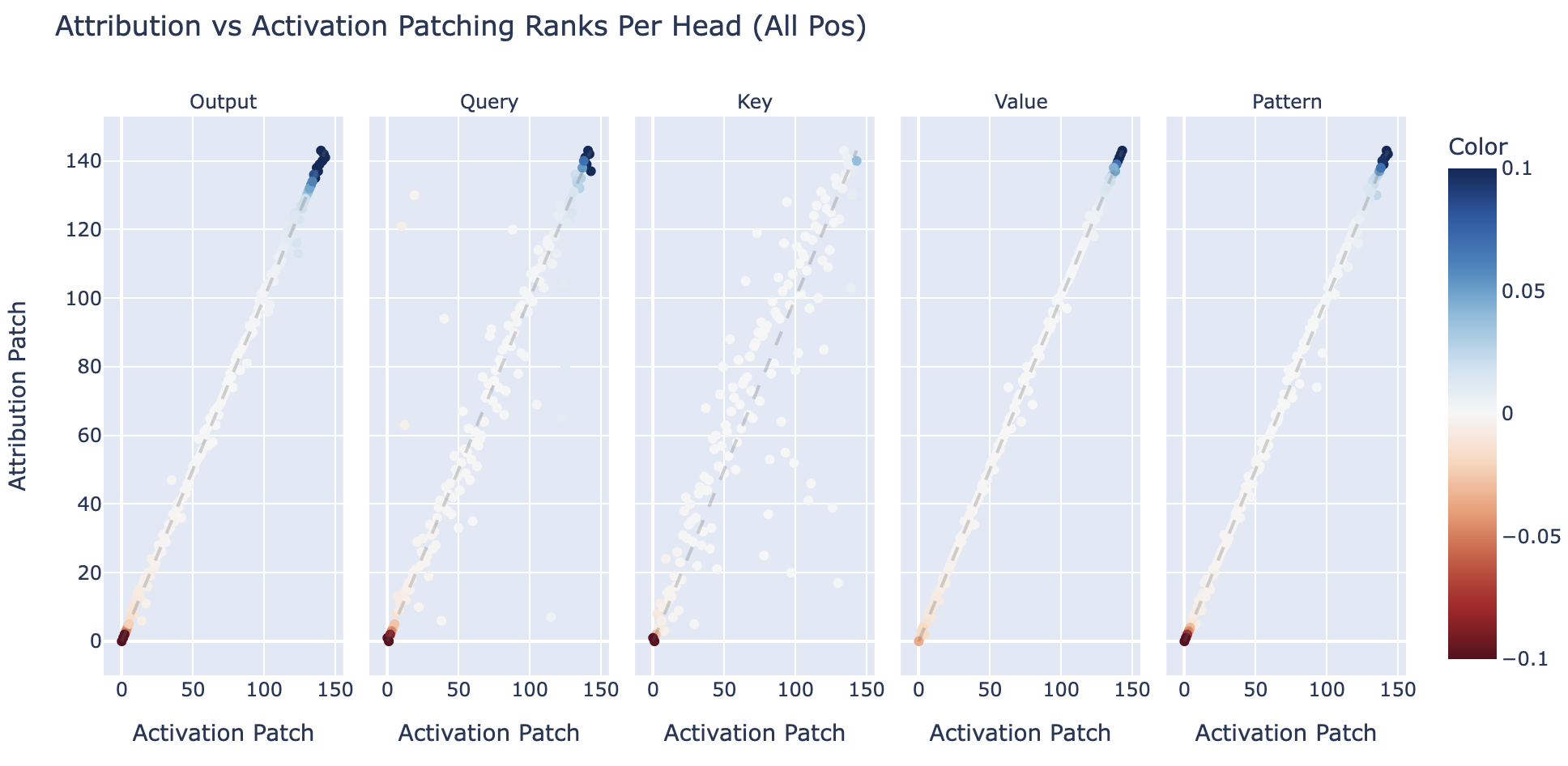
Fun observations
An interesting anomaly is backup heads. These are a circuit in GPT-2 Small where when a name mover head is ablated the other heads compensate for it (presumably because of GPT-2 Small being trained with attention dropout), and mechanistically the other heads seem to be adjusting their attention patterns when the name mover is ablated. But these are non-linear functions (softmax and bilinearity of dot-product attention) which overall cancel out on the full step from corrupted to clean, but which have significant non-linearity in between. In some ways, attribution patching's linear approximation is a feature not a bug here - because this is a significant non-linear function, any linear approximation will likely have a big effect (even if not in the correct direction) and will flag the redundant head as important, even if technically the model will perfectly compensate in practice.
How to Think About Activation Patching
The rest of this post gives a bunch of flavour, thoughts, variants and intuitions on attribution patching, but is not necessary to read to understand the core technique
Before digging further into attribution patching, it's worth dwelling on how to think about patching at all. In later sections I'll focus on arguing that attribution patching is a good approximation to activation patching, so it's worth thinking first about what activation patching is doing, and what it can and can't tell us! I'm particularly satisfied with this section and the next for helping clarify my personal take on patching, and hope it's useful to others too!
What Is the Point of Patching?
The conceptual framework I use when thinking about patching is to think of a model as an enormous mass of different circuits. On any given input, many circuits will be used. Further, while some circuits are likely very common and important (eg words after full stops start with capitals, or "this text is in English"), likely many are very rare and niche and will not matter on the vast majority of inputs (eg "this is token X in the Etsy terms and conditions footer" - a real thing that GPT-2 Small has neurons for!). For example, on IOI, beyond the actual IOI circuit, there is likely circuits to:
- Detect multi-token words (eg names) and assemble them into a single concept
- Detect that this is English text
- Detect that this is natural language text
- Encode unigram frequencies (under which John is 2-3x as likely as Mary!)
- Copying all names present in the context - if a name is present in the text it's way more likely to occur next than an unseen name!
- That this is the second clause of a sentence
- That Indirect Object Identification is the right grammatical structure to use
- That the next word should be a name
As a mech interp researcher, this is really annoying! I can get traction on a circuit in isolation, and there's a range of tools with ablations, direct logit attribution, etc to unpick what's going on. And hopefully any given circuit will be clean and sparse, such that I can ignore most of a model's parameters and most activation dimensions, and focus on what's actually going on. But when any given input triggers many different circuits, it's really hard to know what's happening.
The core point of patching is to solve this. In IOI, most of the circuits will fire the same way regardless of which name is the indirect object/repeated subject. So by formulating a clean and corrupted input that are as close as possible except for the key detail of this name, we can control for as many of the shared circuits as possible. Then, by patching in activations from one run to another, we will not affect the many shared circuits, but will let us isolate out the circuit we care about. Taking the logit difference (ie difference between the log prob of the correct and incorrect answer) also helps achieve this, by controlling for the circuits that decide whether to output a name at all.
Importantly, patching should be robust to some of our conceptual frameworks being wrong, eg a model not having a linear representation, circuits mattering according to paths that go through every single layer, etc. Though it's much less informative when a circuit is diffuse across many heads and neurons than when it's sparse.
Whenever reasoning about patching, it's valuable to keep this in mind! And to be clear to yourself about what exactly is the scope of your investigation - which circuits do you want to identify, how well have you controlled for the irrelevant circuits, what aspects of the circuits you do care about have you accidentally controlled for, etc. And even if you want to identify several circuits, it's generally best to try to have several types of clean and corrupted inputs, so that you can isolate out each circuit one at a time (eg in the Python docstring circuit).
Patching Clean to Corrupted vs Corrupted to Clean
One surprisingly subtle detail is whether you patch a clean activation into the corrupted run, or vice versa. At first glance these seem pretty similar, but I think they're conceptually very different. In the case of IOI, there's a symmetry between clean and corrupted (we could switch which one is clean vs corrupted and it would work about as well), because both are using the IOI circuit but on different names. So it's easier to think about it as the corrupted as the ABC prompt "John and Mary ... Charlie" rather than ABA "John and Mary ... John" - now the corrupted run doesn't need IOI at all!
Terminology can get pretty gnarly here. My current preferred terminology is as follows (I wrote this post before deciding on this terminology, so sorry if it's a bit inconsistent! In particular, I often say activation patching when I should maybe say causal tracing):
- Activation patching covers both directions, and is the process of taking activations from one run and patching them into another run.
- Attribution patching can also go both ways - I focus on clean -> corrupted in this post, but it works exactly the same the other way round.
- Causal tracing is clean -> corrupted. Conceptually this is about finding the activations that are sufficient to recover clean performance in the context of the circuits/features we care about
- If we can patch a head from "The Eiffel Tower is in" to "The Colosseum is in" and flip the answer from Rome to Paris, that seems like strong evidence that that head contained the key information about the input being the Eiffel Tower!
- This finds sufficient activations. If many heads redundantly encode something that quickly saturates, then you can get good logit diff from patching in any of them, even if none of them are necessary
- In the circuit A AND B this tells us nothing, but in A OR B it tells us that both A or B is totally sufficient on its own
- A key gotcha to track is how much this is breaking performance in the corrupted case vs causing the clean performance. In the case of IOI, with symmetric corrupted as name order ABAB and clean as ABBA, the logit difference goes from -x to x. So you can get 50% logit diff back by just zero ablating the logits - it's uniform on everything, so the logit diff is zero!
- While if you find eg a significant increase in the Paris logit for factual knowledge, since Paris is just one out of many possible cities, this is great evidence that the head is doing something useful!
- Though log prob on its own can be misleading, since softmax inhibits smaller logits. If previously the Rome logit was 100 and everything else was 0, then taking Rome from 100 to 0 will significantly increase all other logits. Something like Paris - Berlin logit diff might be most principled here.
- While if you find eg a significant increase in the Paris logit for factual knowledge, since Paris is just one out of many possible cities, this is great evidence that the head is doing something useful!
- Resample ablation is corrupted -> clean. Conceptually this is finding the activations that are necessary to have good clean performance in the context of the circuits/features we care about
- If the model has redundancy, we may see that nothing is necessary! Even if in aggregate they're very important.
- In the circuit A OR B, resample ablating does nothing. But in A AND B it tells us that each of A or B being removed will totally kill performance.
- Note that this naturally extends to thinking of corrupted activations as not necessarily being on a specific prompt - replacing with zeros is ablation, means is mean ablation, you can add in Gaussian noise, etc.
- Here, in some sense, the point is to break performance. But it's worth tracking whether you've broken performance because you've cleverly isolated the circuit you care about, or for boring reasons like throwing the model off distribution.
- If you zero ablate the input tokens you'll destroy performance, but I'm not sure you've learned much :)
- If the model has redundancy, we may see that nothing is necessary! Even if in aggregate they're very important.
In all of the above I was describing patching in a single activation, but the same terminology totally works for patching in many (and this is often what you need to do to get traction on dealing with redundancy)
What Do I Mean By "Circuit"?
By circuit, I mean some fuzzy notion of "an arrangement of parameters that takes some features in and compute some new features". Input features can be input tokens or any earlier computed feature (eg output by some neuron activation), and output features can be attention patterns, output logits, or anything that's just written to the residual stream.
This is actually a pretty thorny concept and I don't have great definitions here, so I will instead gesture at the thorns. There's not a clean distinction between a big end-to-end circuit from the input tokens to the output logits (like IOI) and the many small circuits that compose to make it up (like the one that detects which name is duplicated). Most work so far has focused on end-to-end circuits because the input tokens and output logits are obviously interpretable, but I expect that in large models it's more practical to think of most circuits as starting from some earlier feature, and ending at some later feature, with each feature/circuit used in many end-to-end circuits. There's also not a clear distinction between a single big circuit vs many circuits happening in parallel. Eg "full stops are followed by capital letters" could be implemented with a separate neuron to boost all tokens with " A...", another for Bs, etc - is this one circuit or 26?
How does redundancy & superposition change the picture?
This picture is made significantly messier by the existence of redundancy and by superposition.
Superposition is when a feature is represented as a linear combination of neurons, and implicitly, each neuron represents multiple other features as part of different linear combinations (notably, this means that you can compress in more features than you have neurons!). But, importantly, each feature is rare - on any given input, probably none of a neuron's constituent features are present! (If there were more than 1 feature present, there's costly interference, so superposition likely tries to avoid this). This means that on the patching distribution, probably none of the competing features are present, and so, conditional on those features not being present, each of the neurons in linear combination should be sufficient on its own to somewhat recover performance. This means we'll likely see lots of redundant components doing similar things, but at the cost of forming a somewhat brittle understanding that only partially captures what a neuron truly does - it can do very different things in other settings! And in practice, we often observe many, seemingly redundant heads doing the same thing in circuits, such as the many heads in each class for the IOI circuit (though it's unclear how superposition works in heads, or whether it occurs - potentially each head represents many features, but no feature is represented as a linear combination of heads). Though it's hard to distinguish superposition from there being multiple similar but distinct features!
By redundancy, I can mean two things. There's parallel redundancy where eg multiple heads or neurons are representing the same thing simultaneously (they can be in different layers, but importantly are not composing - ablating one should not affect the output of the others) and serial redundancy where head 2 will compensate for head 1 in an earlier layer being damaged - ie, head 2 does nothing relevant by default, but if head 1 is ablated or otherwise not doing its job, then head 2 will change its behaviour and take over.
Parallel redundancy is totally fine under patching, and pretty easy to reason about, but serial redundancy is much more of a mess. If you resample ablate head 1, then head 2 may just take over and you'll see no effect! (Unless you got lucky and your patch preserved the "I am not damaged" signal). Ditto, copying in something that just damages head 1 may trigger head 2 to take over, and maybe head 2 will then do the right thing! The backup and negative name movers in IOI exhibit both kinds of redundancy, but I think the serial redundancy is much more interesting - if you zero ablate head L9H9 then a negative name mover and backup name mover in subsequent layers will significantly increase their direct logit attribution!
Redunancy makes it significantly harder to interpret the results of patching and I don't really know what to do about it - it's hard to attribute the effect of things when one variable is also a function of another! I consider causal scrubbing to be a decent attempt at this - one of the key ideas is to find the right set of components to resample ablate to fully destroy performance.
But does redundancy occur at all? In models trained with dropout (of which I believe GPT-2 is the main public example, though this is poorly documented) it's clear that models will learn serial redundancy - if component 1 is dropped out, then component 2 takes over. In particular, attention dropout is sometimes used, which sets each attention pattern weight (post softmax) to 0 with 10% probability - if there's a crucial source -> dest connection, storing it in a single head is crazy! This also incentivises parallel redundancy - better to diversify and spread out the parts that can be dropped out rather than having a single big bet.
Modern LLMs tend not to be trained with dropout, so does this still matter? This hasn't been studied very well, but anecdotally redundancy still exists, though to a lesser degree. It's pretty mysterious as to why, but my wild guess is that it comes from superposition - if a neuron can represent both feature A and feature B, then if both feature A and feature B are present, the model's ability to compute either feature will be disrupted. This may be expensive, and worth learning some backup circuits to deal with! (Either serial or parallel redundancy may be used here) In fact, parallel redundancy can be thought of as just superposition - if neuron A and neuron B represent feature X, then we can think of the linear combination of both neurons as the "effective" neuron representin X.
What Can('t) Activation Patching Teach Us?
Thanks to Chris Olah for discussion that helped significantly clarify this section
The beauty of activation patching is that it sets up and analyses careful counterfactuals between prompts, and allows you to isolate the differences. This can let you isolate out a specific part of model behaviour, conditional on various others, and importantly, without needing to have understood those other behaviours mechanistically! Eg, understanding how the model identifies the name of the indirect object, given that it knows it's doing IOI, but not how it knows that it's doing IOI. But this is a double-edged sword - it's important to track exactly what activation patching (and thus attribution patching!) can and cannot teach us.
The broader meta point is that there's two axes along which techniques and circuits work can vary:
- Specific vs general - how much the work is explaining a component or circuit on a specific distribution (eg the distribution of sentences that exhibit IOI or repeated random tokens) vs explaining it in full generality, such that you could confidently predict off distribution behaviour.
- Complete vs incomplete - whether the work has fully characterised how the model component does its task, vs whether it has significant flaws and missing pieces.
Being too specific or being incomplete are two conceptually distinct ways that work can be limited. The induction heads work has been suggested to have been missing important details, and criticised accordingly, but this is a critique of incompleteness. It's not that the heads aren't doing induction in the sense of "detecting and continuing repeated text", but that in addition to just the strict mechanism of A B ... A -> B, the heads did fuzzier things like checking for matches of the previous several tokens rather than just the current one.
Meanwhile, the work on the IOI circuit was too specific in the sense that the identified heads could easily be polysemantic and doing some completely different behaviour on a different distribution of text.
Specific vs general work
I think that the notion of specific vs general work is an important one to keep in mind, and worth digging into. In my opinion, basically all transformer circuits work has skewed to the specific, while the curve circuits work in image models comes closest to being general. Patching-style techniques (activation patching, attribution patching, causal scrubbing, path patching, etc) fundamentally require choosing a clean and corrupted distribution, ideally fairly similar distributions, and thus skew towards the specific (though can be a good first step in a general investigation!). For example, the IOI work never looked at the circuit's behaviour beyond the simple, syntactic, IOI-style prompts.
The induction heads work feels closest to being general, eg by making predictions about head behaviour on repeated random tokens, and looking at the effect on in-context learning across the entire training data distribution.
In some ways, patching-style specific techniques are much easier than aiming for general understanding, and my sense is that much of the field is aiming for specific goals at the moment. It's not obvious to me whether this is a good or bad thing (and I've heard strong opinions in both directions from researchers), but it's worth being aware that this is a trade-off. I think that specific work is still valuable, and it's not clear to me that we need to get good at general work - being really good at patching-style work could look like creating great debuggers for models, disentangling how the model does certain tasks, debugging failures, and isolating specific features we care about (ambitiously, things like goals, situational awareness or deception!). But general work is also valuable, and has been comparatively neglected by the field, and may be crucial for predicting network behaviour off distribution (eg finding adversarial examples, or ambitiously, finding treacherous turns!), for deeply understanding a network and its underlying principles in general, auditing models and getting closer to finding guarantees about systems, eg that this will never intentionally manipulate a user.
Much of the promise of mech interp is in really understanding systems, and a core hypothesis is that we can decompose a system into components with a single, coherent meaning. In particular, we'd like to be able to predict how they will generalise off distribution, and an incomplete but general understanding may be far more useful here than a complete but specific understanding! Specific or incomplete work can still be valuable and insightful, but this weakness important to track.
Further, an extremely nice outcome of mechanistic analysis would be if we could somehow catalogue or characterise what different model components do, and then when observing these components arising in new circuits, use our existing understanding to see what it means for things to compose. This is a hard and ambitious goal and likely only properly achievable if we can deal with superposition, but aiming for this skews hard towards aiming for general analysis over specific analysis.
I think that patching-based techniques are great to build a better understanding of a circuit, and especially to heavily narrow down the search space of possible hypotheses, but it's important to keep in mind that they're fairly specific. Variants like causal scrubbing are powerful approaches to study completeness, but are still tied to a distribution. This is a spectrum, of course, and the broader and more general the distribution is, the more compelling I find the results - if we can causally scrub some hypothesis and fully recover loss on the entire data distribution (or on an even more diverse distribution), I feel pretty compelled by that!
What Would It Look Like to Aim for General Understanding?
I think it's worth dwelling on what aiming for general understanding might look like. Here's an attempted breakdown of what I see as the main approaches here. This all comes with the caveat that "general understanding" is a fairly messy and thorny question and seems very hard to achieve perfectly and with high confidence (if it's even possible). My thoughts here focus more on what evidence directionally points towards a more vs less general understanding, more so than showing a truly universal understanding of a model component:
- Mechanistic analysis: Actually analysing the weights of the model, and recovering the hypothesised algorithm.
- Eg Looking at the weights of the two composing attention heads to see that they form an induction circuit that can do strict induction in general.
- It's worth noting that this is weaker evidence than it can seem at first glance. Models are complex and messy objects, and mechanistic analysis tends to involve steps like "ignore this term because it doesn't seem important".
- Refinements like "replace the model's weights/component with our mechanistic understanding" and analysing loss/accuracy recovered on the full data distribution are stronger. Eg hand-coding the neurons in curve circuits, or ablating irrelevant weights and activations in my modular addition work.
- Though even this can be misleading! Eg if the model has some learned redundancy, even fully ablating a component may not reduce loss that much.
- Analysing behaviour on the full data distribution: The obvious way to deal with the criticism that you're focusing on a narrow distribution is to look at a component over the full data distribution, and see if your understanding fully explains its behaviour. This is hard to do right (the data distribution for a language model is very big!) but can be very compelling.
- One angle is spectrum plots, a technique for understanding neurons. Eg if we think a neuron only fires for number tokens, we can run the model on a bunch of text, and plot a histogram of neuron activations on number and non-number tokens - if the neuron truly only fires on numbers, then this should be very obvious (though there's likely to be a bunch of noise, so if the two categories overlap a bit this may be fine).
- Spectrum plots require automated tools to do on a large sample size, but a more tractable version is just to study a model component on random dataset examples, and see how well our understanding predicts behaviour.
- Anecdotally, when induction heads are studied on random dataset examples they tend to "look induction-y" and be mainly involved in repeated text tasks
- This motivates a natural refinement of looking at neuron max activating dataset examples - looking at a few random samples from different quantiles along the full distribution of activations, eg a few around the 95th percentile, 90th percentile, 75th percentile and 50th percentile. If these match your overall understanding, that's much more compelling!
- Generalising to other distributions: If you understand a model on a narrow distribution and then widen this distribution, does your understanding still hold? If yes, this is evidence that your understanding is general - and the broader your new distribution is, the better (if it's the full training distribution, that's great!).
- Using your mechanistic understanding to come up with adversarial examples, as with typographic attacks on CLIP and in interpretability in the wild.
- More ad-hoc approaches, eg induction heads working on repeated random tokens.
- Using your mechanistic understanding to come up with adversarial examples, as with typographic attacks on CLIP and in interpretability in the wild.
- Independent-ish techniques: A meta point is that if you have multiple techniques that intuitively seem "independent" in the sense that they could easily have disagreed, this makes the evidence of generality become more compelling, even if each piece of evidence on its own is questionable.
- Eg max activating dataset examples on their own can be highly misleading. But if they also match what was found independently when patching a neuron, that feels much more compelling to me.
- Ditto, if the max activating dataset examples for a late layer neuron explain the direct logit attribution of the neuron (eg a neuron always activates on full stops and boosts tokens beginning with a space and capital letter).
- Note that I use "independent" in an informal sense of "genuinely provides new Bayesian evidence, conditioning on all previous evidence", rather than "conditioning on previous evidence tells you literally nothing"
- But these are just examples, there's likely a wide range of more ad-hoc approaches that are pretty specific to the question being asked.
- Eg the fact induction heads form as a phase change and this seems deeply tied to a model's capacity for in-context learning. The fact that they're such a big deal as to cause a bump in the loss curve, and that this seems tied to in-context learning, is pretty strong evidence that "being induction-y" is core to their overall function in the model.
Caveats:
- Generality lies on a spectrum - components can be more or less general, and the above are mostly techniques for showing an understanding is more general. To show that a model component literally only does a single thing seems extremely hard.
- I think this is still an interesting question! In my opinion there's a meaningful difference between "this head is sometimes inductiony" and "on 99% of random dataset examples where this head matters, it's induction-y"
- In particular, it's plausible that models use superposition to represent sparse and anti-correlated features - if the component does something else on 0.01% of inputs, this can be pretty hard to notice! Even with approaches like "replace the component with hand-coded weights and look at loss recovered", you just won't notice rare features.
- I think generality is best thought of as an end goal not as a filter on experiment ideas - you shouldn't discard an experiment idea because it looks at a narrow distribution. Narrow distributions and patching are way more tractable, and can be a great way to get a first understanding of a model component.
- But you need to then check how general this understanding is! For example, I think that a great concrete open problem would be checking how well the indirect object identification circuit explains the behaviour of the relevant heads in GPT-2 Small on arbitrary text.
- I've deliberately been using "component" rather than "head" or "neuron" - I think it's hard to talk clearly about generality without having better frameworks to think about and deal with superposition. Plausibly, a truly general understanding looks more like "this linear combination of neurons purely represents this feature, modulo removing any interference from superposition"
- It's also plausible that there's no such thing as a truly general understanding, that superposition is rife, and the best we can get is "this neuron represents feature A 25% of the time, and feature B 75% of the time"
- Note that with many of the more circumstantial approaches above need to be done in a scientifically rigorous and falsifiable way to be real evidence.
- If you discover induction heads by just studying a model on natural language, predict that they'll generalise to repeated random tokens (and that models can predict those at all!) then this is strong evidence - the experiment could easily have come out the other way! But if you identified induction heads by studying the model on both repeated random tokens and repeated natural language, the evidence is much weaker.
As an interesting concrete case study, a study of a docstring circuit in a four layer attention-only model found that head L1H4 acted as an induction head in one part of the circuit and a previous token head in another part, and further investigation suggests that it's genuinely polysemantic. On a more narrow distribution this head could easily exhibit just one behaviour and eg seem like a monosemantic inductin head. Yet on the alternate (and uncorrelated) test of detecting repeated random tokens it actually does very badly, which disproves that hypothesis.
Does This Make Any Sense?
This section is intended to provide a bunch of illustrative intuition, at the cost of getting somewhat into the weeds
So, does any of this make any sense? "Assume everything is linear" is an extremely convenient assumption, but is this remotely principled? Is there any reason we should expect this to help us form true beliefs about networks?
My overall take is, maybe! Empirically, it holds up surprisingly well, especially for "smaller" changes, see the experiments section section below. Theoretically, it's a fair bit more principled than it seemed to me at first glance, but can definitely break in some situations. Here I'll try to discuss the underlying intuitions behind where the technique should and should not work and what we can take from it. I see there as being two big questions around whether attribution patching should work, whether the relevant circuit component has linear vs non-linear structure and whether it has single feature or multi-feature dependence.
My headline take is that attribution patching does reasonably well. It works best when patching things near the end of the model, and when making "small" patches, where patch represents a small fraction of the residual stream, and badly for big patches (eg an entire residual stream). It works best on circuits without too many layers of composition, or which focus on routing information via attention heads, and will work less well on circuits involving many layers of composition between very non-linear functions, especially functions with a few key bottleneck activations that behave importantly non-linearly (eg a key attention pattern weight that starts near zero and ends up near one post patch). And it works best when the clean and corrupted prompts are set up to differ by one key feature, rather than many that all compose.
Single vs Multi Features Dependence
The intuition here is that we can think about the model's activations as representing features (ie, variables), and components calculating functions of these features. For example, Name Mover Heads in the IOI circuit have the Q input of which names are duplicated and K input of what names exist in the context, and calculate an attention pattern looking at each non-duplicated name. We can think of this as a Boolean AND between the "John is duplicated" Q feature and the "John is at position 4" and "Mary is at position 2" K features.
The key thing to flag is that this is a function of two features, and will not work if only one of those features is present. I call this kind of thing multi-feature dependence. Linear approximations, fundamentally, are about assuming that everything else is held fixed, and varying a single activation, and so cannot pick up on real multi-feature dependence. Note that multi-feature dependence is not the same as there being multiple features which all matter, but which act in parallel. For example, the IOI circuit has a component tracking the position of the duplicated name, and a component tracking the value (ie which name) - these are multiple features that matter, but mostly don't depend on each other and either on its own is highly effective, so attribution patching can pick up on this. Another way of phrasing this is that attribution patching can pick up on the effect of each feature on its own, but will neglect any interaction terms, and so will break when the interaction terms are a significant part of what's going on.
When we take a clean vs corrupted prompt, we vary the key features we care about, but ideally keep as many "contextual" features the same as possible. In our example from earlier, activation patching the residual stream at the final token only patches the "John is duplicated" feature and so only patches in the Q feature, not the K feature. But the K feature is held fixed, so this is enough to recover performance! Meanwhile, if we patched into a prompt with different names, or arbitrary text, or whatever, the activation patching would break because the "contextual" K feature of where John and Mary are would break. However, if we patched in the relevant features at Q and at K, we're good (eg patching in thxe direct path from the pos 2 and pos 4 embedding, and the output of the S inhibition heads on the final token).
So we can think of the name mover's attention pattern as a multi feature function in general, but in the specific context of the clean vs corrupted prompt we setup it's locally a single feature function. Attribution patching fundamentally assumes linearity, and so will totally break on multi-feature dependence, but so will activation patching, unless we patch in all relevant features at once. This can happen, especially when doing fancier kinds of activation patching, but I generally think activation patching is the wrong tool to notice this kind of thing, and it's normally a sign that you need to choose your clean and corrupted prompts better. Though generally this is just the kind of question you'll need to reason through - prompts can differ in a single feature, which is used to compute multiple subsequent features, each of which matter.
Activation patching is more likely to capture multi-feature dependence when we patch in a "large" activation, eg the entire residual stream at a position, which we expect will contain many features. And, in fact, residual stream attribution patching does pretty badly!
Further, patching something downstream of a multi-feature function (eg its output) should work (as well as single-feature) for either activation or attribution patching. Eg, if doing factual recall on Bill Gates, patching in the tokens/token level functions of either " Bill" or " Gates" in isolation will do pretty badly. But if we patch in something containing the "is Bill Gates" feature (eg, the output of a "Bill Gates" neuron, or an early-mid residual stream on the right token) we're fine.
Linear vs Non-Linear (Local) Structure
The second way that a linear approximation can break is if, well, the function represented by the model is not linear! Transformers are shockingly linear objects, but there are five main sources of non-linearities - the attention pattern softmax, MLP neuron activations, the multiplication of value vectors at source positions by the attention pattern, LayerNorm normalisation, and the final softmax. Generally, each of these will be locally linear, but it's plausible that activation patching might be a big enough change to that function that linearity loses a lot of information.
This is a high-level question that I want to get more empirical data on, but my current intuition is that it will depend heavily on how much the patch being approximated moves non-linearities from a saturated to an unsaturated region. By saturated, I mean a region where the derivative is near zero, eg the log prob of a token the model is really confident comes next, an attention pattern weight that's close to zero or one, or well into the negative tail of a GELU. If there's an important activation that goes from a saturated to unsaturated region, a linear approximation says nothing happens, while activation patching says a lot changes.
One useful observation to help reason about this is that an attention softmax becomes a sigmoid if you hold all other variables fixed, and that the final log softmax is linear for large negative logits, and slowly plateaus and asymptotes to $y=0$ for large positive logits. (And if we're assuming single variable dependence, then "holding everything else fixed" can be a reasonable assumption).
This is generally an area where I struggle to be precise - in some contexts this linear approximation will totally break, in others it will be fine. If most non-linearities are not in a saturated region, a linear approximation may be reasonable, and if they become saturated post-patch, we'll just overestimate their importance which seems fine (false positives are much better than false negatives!).
LayerNorm
A particularly thorny non-linearity is the normalisation step of layer norm (where the input vector is mapped to be standard deviation 1, ie norm $\sqrt{d_{model}}$). This is the high-dimensional equivalent of projecting a 2D vector onto the unit circle, and is almost linear.
The directional derivative of the map $v \to |v|$ is $\frac{v}{|v|}$ - moving infinitessimally orthogonal to the vector makes no difference, while moving along the direction of the vector scales the norm linearly. From this we can derive that the derivative of LayerNorm normalisation is the complete opposite - the component in the direction of $v$ is zero (because it scales $v$ and its norm equally and cancels out) and the component in any direction orthogonal to $v$ is unchanged, because it has no effect on the norm.
This, in practice, means that if the direction being patched is orthogonal to the residual stream at a particular layer, then taking the derivative will just ignore LayerNorm (ie treat it as linear), while if the direction being patched is parallel to the residual stream at the relevant layer, then the derivative will say that the patch has zero effect on that layer's output.
In a high dimensional space, any pair of vectors are almost orthogonal, unless they're significantly correlated. And in general, the residual stream is full of a lot of stuff, most of which is not relevant to the current circuit. So my guess is that for "small" patches this doesn't matter that much. But for large, eg residual stream patches, this will completely break things, which is another reason why residual stream patching works badly! I found this pretty surprising at the start of this investigation - we expected residual stream patching near the final layer to work near perfectly, since it was logit focused and thus basically linear, but turns out that LayerNorm completely breaks things.
One possible patch for this is to just treat the LayerNorm normalisation factors as constants - I think this is principled if the model does not use LayerNorm as a meaningful non-linearity to do computation, and pretty broken if it does. Whether this happens is an open question, but my guess is that attribution patching is the wrong tool to detect this. In PyTorch this is generally implemented with stop_gradients, but in TransformerLens you can do it hackily with no code changes by just patching in previously cached activations to replace the LayerNorm normalisation factors (called hook_scale) so there are no gradients to take.
My Guesses for Where Attribution Patching Works
The following are my wild speculations, with some limited empirical backing
- Places attribution patching works badly
- MLP heavy circuits
- Circuits where a few MLPs matter a lot, since they're more likely to be saturated
- Circuits where many MLPs matter, most are not saturated, and there's not significant MLP-MLP composition may be fine?
- Early layers of circuits with many layers composing in important ways
- In particular, patching at the embedding will likely work terribly, since I doubt the embedding has a remotely linear/continuous structure, and because the inputs are discrete.
- Contexts with multi-variable dependence
- In particular, where we need to patch single big activations, or many activations at once, where each individual patch does nothing.
- Circuits where there's a few crucial attention pattern weights that start very close to zero or one
- When we patch a "big" activation, like the residual stream
- MLP heavy circuits
- Places where attribution patching should work well
- Towards the end of circuits (either in absolute terms, near the end of the network, or in relative terms in a circuit without much nested composition)
- The "end" of a circuit can be in the middle of the model, where our "metric" is based on an activation eg the score of how induction-y a head's attention pattern is, or a specific neuron's activation.
- Circuits to do with routing information, where much of the interesting composition is with the OV circuits of attention heads moving features between positions
- Patches involving incremental changes in key activations (eg attention pattern weights going from 0.3 to 0.7) rather than very big changes
- Small, targeted patches, where eg one head or one neuron's output is really important.
- Towards the end of circuits (either in absolute terms, near the end of the network, or in relative terms in a circuit without much nested composition)
Patching Variants
Both kinds of patching are interesting and versatile techniques, with a lot of room to vary them. In this section I detail two variants I'm particularly excited about - path patching and attention pattern patching, and how to do them with attribution patching, including a variant I call attention attribution that requires no corrupted prompt, followed by a broader brain-dump of interesting axes of variation.
Path patching
The core intuition behind path patching is to think of a model as a computational graph, where each node is a component (layer, head, neuron, etc) which reads and writes from the residual stream. And with a start node (embeddings) and an end node (logits, and then log probs). Each pair of nodes in different layers has an edge from the early node to the late node, representing the composition of the two. The residual stream is the sum of the output of all previous components, so the input to node 2 can be broken down into the sum of many components including the output of node 1. We generally think of attention heads as having 3 inputs (Q, K and V) and a single output. We can think of a circuit as both a subgraph of nodes (finding the relevant components) but also as a subgraph of edges (finding which of the key components compose and ideally how).
Activation patching as I've framed here is focused on patching nodes, but it can also be extended to study edges, where we only patch the output of node 1 into the input to node 2 (ie subtract the corrupted output of node 1 and add the clean output from the residual stream as input to node 2, but keep every other node's input the same). This is called direct path patching (I believe this was first introduced in Interpretability in the Wild, though they reserve the term path patching for a more complicated technique).
A simple case of direct path patching is direct logit attribution - looking at the direct contribution of each component's output to the logits. If we look at the difference between the direct logit attribution of a clean and corrupted activation, this is just direct path patching to the logits!
Path patching is exciting because it can give an extremely zoomed in understanding of what's going on in the model and how parts compose together, which can be much more useful for interpreting what's going on in a circuit. This holds even more strongly if we have a separate set of nodes at each position (where all edges are within the same position, but attention head K and V inputs at a source position may affect any output position). And, generally, the number of important nodes is small and sparse enough that a circuit's compositional structure can just be read off the patched computational graph.
The obvious problem is that path patching is quadratic in the number of nodes, while activation patching is linear, making it even more expensive! We can extend attribution patching to direct attribution path patching to make this much easier. Rather than having the formula ((clean_act - corrupted_act) * corrupted_grad_act).sum(), we have the formula ((clean_early_node_out - corrupted_early_node_out) * corrupted_late_node_in_grad).sum(), where all three vectors live in the residual stream - this is more expensive to calculate than node based attribution patching since it involves a linear time operation across all pairs of nodes, but is still much faster (especially if it can be done as a matrix multiply between an [early_nodes, d_model] and [late_nodes, d_model] matrix). Further, patching a single path is a very small change, and so it is even more plausible that a linear approximation is reasonable! Note that, because of linearity, the sum of the path attribution patch values over all start nodes (including the embedding) should equal the end node's total attribution patch value.
corrupted_late_node_in_grad is the gradient of the metric with respect to the residual stream but only as mediated by node 2. Intuitively, you can picture cloning the residual stream before node 2 - the copy is input to node 2, but everything else uses the original. The derivative of the metric with respect to the copy is corrupted_late_node_in_grad!
We can do even more fine-grained path patching if we decompose things further. For example, rather than a head's query key and value being a single node per position, we can split them into a node for each source and destination (though it becomes more of a headache to code), or decompose the output into the sum of the component from each source position. We can also split an MLP layer into individual neurons with their own input and output, or even taking arbitrary directions in some overcomplete basis found with some future approach to understanding superposition. Which all get much, much faster with attribution patching!
(Aside) Implementation Details
clean_early_node_out and corrupted_early_node_out are easy to compute from the cached activations from the forward pass, but corrupted_late_node_in_grad is hard. If we actually did fork the residual stream for each component this would be easy (and will soon be an option for attention heads in TransformerLens!) but because things are so linear, it's pretty doable to rederive it. The attached notebook has hacky code to do this for Q, K and V for attention heads - the key idea is that if we know the gradient with respect to a key, and that key is key = residual_stream @ W_K + b_K, then residual_stream_grad_mediated_by_key = W_K @ key (essentially what backprop does, except we focus on the gradient with respect to an activation, not with respect to a parameter).
The gory detail here is LayerNorm, since normalisation makes things technically not linear. I just linearise LayerNorm (pretend the normalisation factor is fixed and divide by it), but it's a bit of a headache.
Results
When we run this on the IOI circuit, we can plot a heatmap for each pair of heads, and see the connections (end heads are split into Q, K and V, and it's lower triangular because end heads are always after start heads).
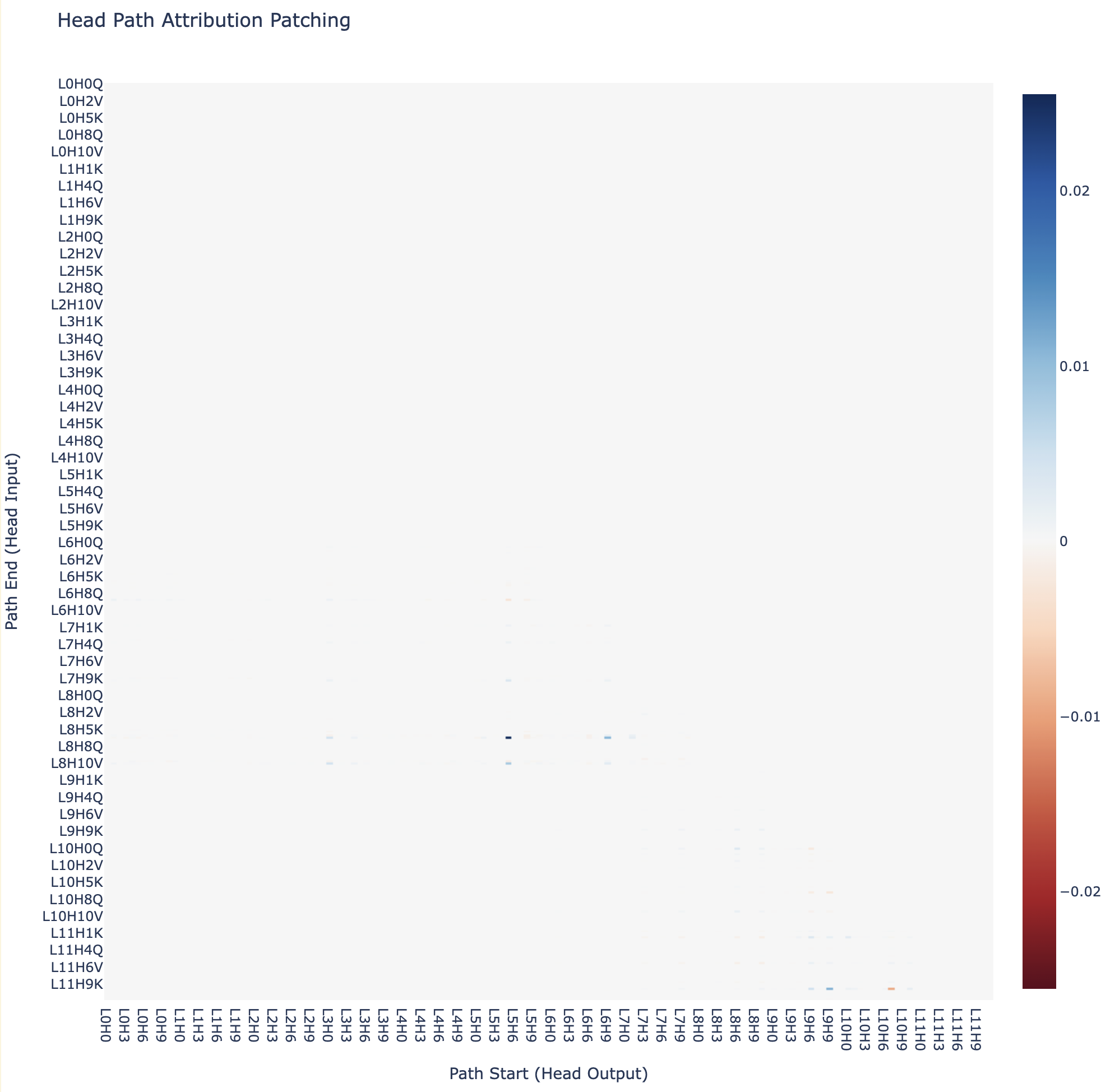
The above heatmap is somewhat difficult to interpret, but we can instantly observe that it is sparse:

Further, if we filter for the top positive and negative paths, we recover (some) key edges in the IOI circuit.

It's somewhat messy, since heads vary a lot in how important their total attribution patch value, and this is distributed amongst all input paths. We can make this more fine-grained by filtering for the heads that we already think are important and showing their input and output paths:
As a reminder, the IOI diagram:

Induction Head L5H5 - it has no inputs (the previous token head behaves the same on either distribution), mostly interacts with S-Inhibition heads. Interestingly it has some Q composition with the other induction head - maybe backup behaviour?

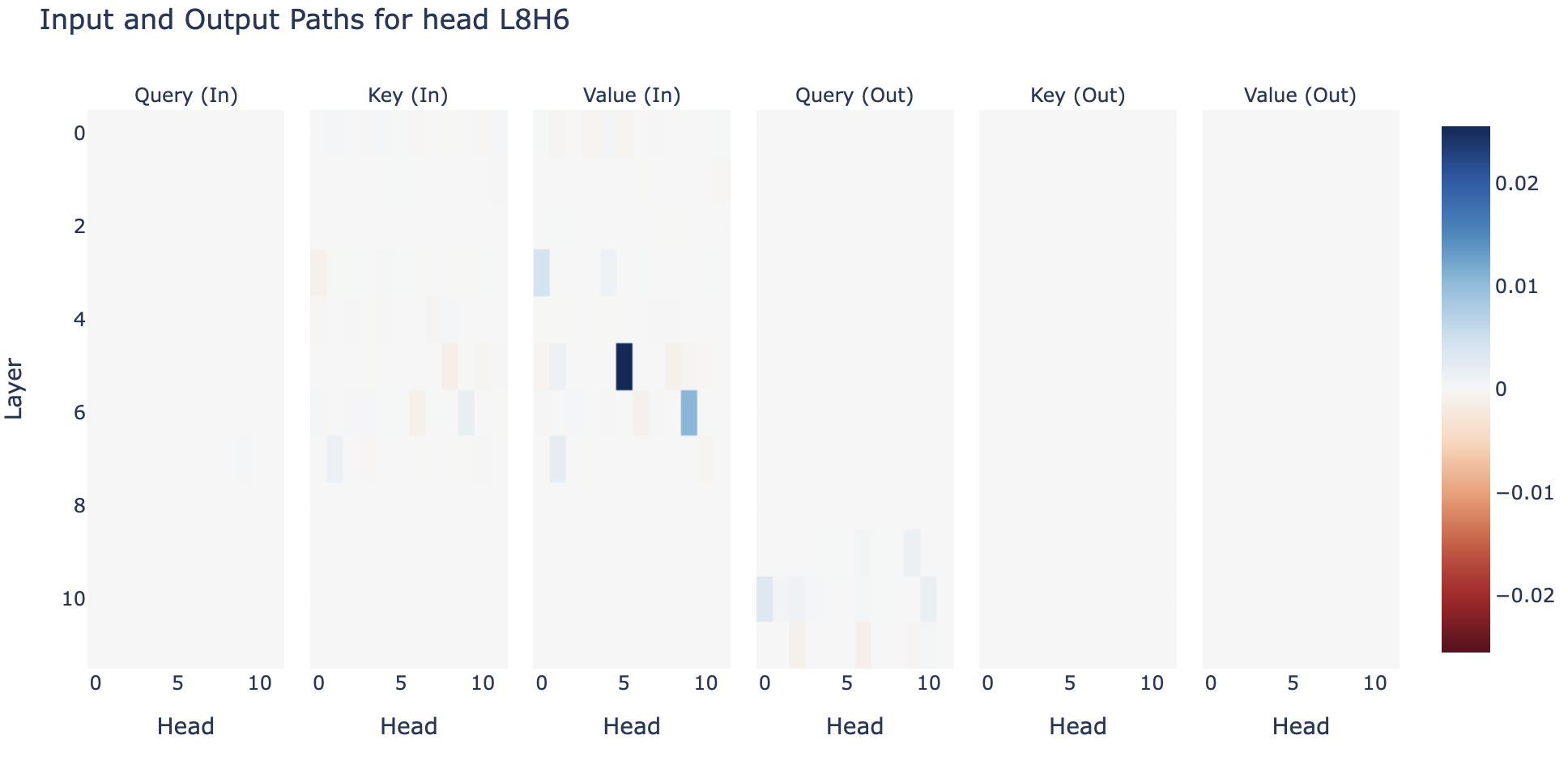
S-Inhibition Head L8H6 - it is strongly impacted by the two induction heads and duplicate token head (L3H0) on the value, and affects a range of name mover type heads via the query
Name Mover L9H9 - It's affected via Q-Composition by the S-Inhibition heads, but surprisingly Q-Composes with some downstream heads, notably the negative name movers, suggesting that there's a significant Q-Composition component to the backup mechanism.
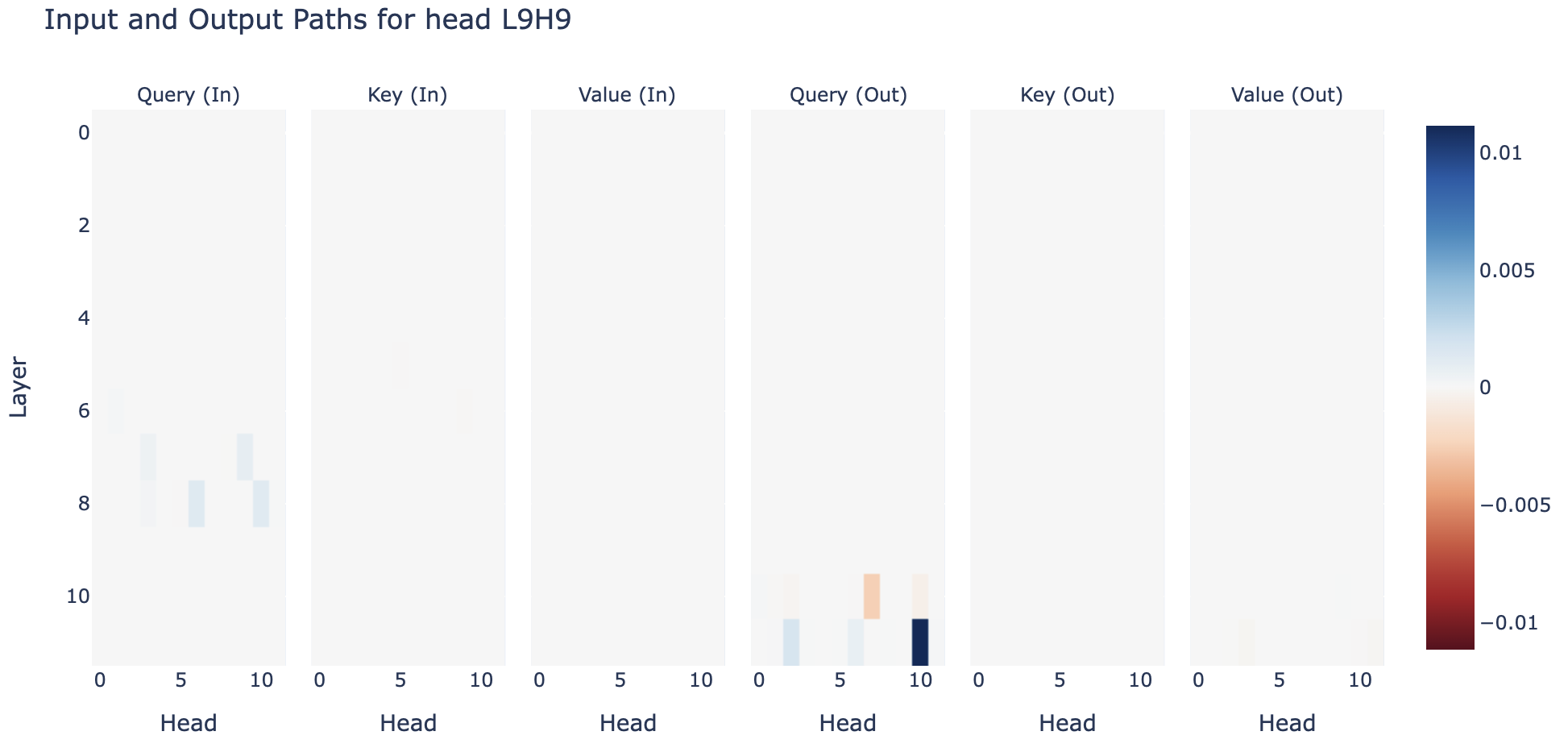
I have explored these results less well than I would have liked, and would be excited to see what you can find if you poke around!
Attention Pattern Patching
An interesting variant is attention pattern patching, where we patch individual attention pattern weights (for a specific head and a specific source and destination position). (I haven't explicitly seen anyone do this, but it's an obvious enough idea that I'm sure someone has tried). It's also a cute technique because it gives you a score for each head and each pair of positions, which you can then feed through an attention pattern visualiser!
One notable thing about transformers is that 1/6 of their parameters go towards calculating where to route information from and to - this is a significant amount of computation! And this often represents significant computation. For example, a name mover head, where the context contains both the indirect object name and the subject name, and the main computation goes towards getting the attention pattern to look at the indirect object name and not the subject name! This is an example of a general motif of a "mover" head whose computation is figuring out which element of the context to look at, and then just copies this to the output logits - induction heads are another example, and I've seen several more in unpublished work.
The two notable things here are that we can disentangle where information is moved from (pattern) and what information is moved conditional on position (value), and further that sometimes there are key connections where amplifying or suppressing those matters a lot. And attention pattern patching can help disentangle this by picking up on which connections matter in terms of where they look, not what they move!
This is a good area to apply attribution patching! You need to do a patch for every head and every pair of positions, which gets expensive on long prompts. And it's very fine-grained, and involves small changes. Further, pattern patching is particularly suitable, because its immediate effect is just scaling the value vector, which is purely linear.
There are further variants possible, for example, looking at each value vector's effect on each destination position (which you can do by dotting each source value vector's change with each destination's z gradient). This isn't very interesting on IOI, where the destination positions are obvious, but could be a useful tool for tracing more complex information flow!
(Aside) Should you patch scores vs patterns?
It seems reasonable to do this for either the attention scores (pre-softmax) or pattern (post-softmax). The scores are unaffected by a constant offset, so it could be unprincipled if clean and corrupted have very different baselines, but this seems unlikely with well chosen prompt pairs. Meanwhile, pattern patching breaks the fact that things sum to one, which could eg break things if a model relies on the attention head producing a bias term (ie the mean of its output is significantly non-zero and used elsewhere), but also is a more direct engagement with how important the connection is.
There are variants that might work even better, eg patching patterns and then re-normalising, factoring out the head's value bias (which TransformerLens does automatically) since its effect on the output is fixed because attention adds to one, or going further and factoring out the average of the value vector across a lot of data (or possibly just the patching distribution)
When we do this on the IOI circuit, we can immediately identify the key connections the important heads. Check out the Attention Pattern Patching section in the notebook to play around with the visualisation.
Attention Attribution
An even dumber variant is to scrap patching altogether - rather than having a clean and corrupted prompt, we just have a clean prompt and clean gradients, and we look at the attention attribution, the pattern-shaped tensor clean_pattern * clean_pattern_grad. This has the same shape as a pattern (though can be positive and negative) and can be put into an attention visualizer, and turns out to be a solid view into how information is moved around the network.
If we sort by the max absolute value of the pattern attribution across heads, we instantly recover a bunch of the important heads, and can see the important connections. And a lot of heads with significant attention to irrelevant tokens have things instantly clarified - those connections have high pattern but low gradient and so low attribution. Check out the Attention Attribution section in the notebook to play around with the visualisation.
Intuitively, we're taking a linear approximation to a zero ablation (rather than patching a clean activation into a corrupted run, we patch a "corrupted" pattern of zeros into a clean run). This technique is pretty janky, but I really like it, because it's simultaneously insightful, and incredibly easy to apply - since you don't need to come up with a corrupted prompt, you can apply this on any text where a head does something interesting.
A pro and con of this approach is that we lose the counterfactual nature of the clean vs corrupted set up, and no longer control for things properly. This means that we also pick up on eg head connections relevant for "figure out that I want a name" or "figure out that I want to be doing IOI at all", which seems to potentially be the case when I apply this to the IOI circuit!
Attribution Patching as a Heuristic
At a high-level, lots of mech interp work is about searching the space of possible circuits to find the ones that actually matter. And search gets a lot easier if you have some fast heuristics to help prune the search space! I think there's a bunch of ways attribution patching can be a useful heuristic.
Attribution patching, as I've laid it out here, is very focused on patching from a clean run to a corrupted run, which differ only in the inputs, but the same principles work for any kind of weird, intervened on or causally scrubbing run. Eg if we have an incomplete guess for what a circuit is (eg we know it involves an induction head, an S-Inhibition Head and a name mover, but are missing the rest), we could take our corrupted run as having everything apart from those heads and connections between them ablated (eg independently randomly sampled from other runs), and then do direct attribution path patching on every input and output from those nodes to find the next edge and node to add in.
Sadly, every edit you make to your guessed graph will change the gradients and thus need another re-computation of attribution patches, but this should still be a significant speed up!
A cool new area of work from Arthur Conmy and collaborators is Automatic Circuit Discover Code (ACDC), which at a high level is basically trying to do this, and to automatically find the most important subgraph of the model on some task (that is, the subset of nodes and edges that are most important to that task) and ideally use this to find automated circuits. I'm not familiar enough with what they're actually doing to have a clear view of the bottlenecks, but hopefully something like attribution patching can be useful there!
Stop Gradients as Edits to the Computational Graph
The above plan required us to edit the computational graph that we're backpropagating through - we only want to do this for the edges and nodes we've decided to include. This turns out to actually be really easy to implement (at least in TransformerLens), since the ablations are inserting tensors that are essentially leaf nodes in the computational graph (either just zero tensors, or activations from other random inputs), through which no gradients can propagate, so we only see the effect of the edges and nodes that we haven't random ablated.
This is a more general principle that allows us to make weird edits to the graph that gradients flow through, by just stopping gradients at some activation. This lets us try patching on various weird kinds of intervention, eg patching in the effect of MLP layer 5 but as mediated by all layers apart from MLP layer 6 and attention layer 6, but just doing a stop gradient on their outputs.
Normally stop gradients are a pain because they require you to edit the code, but in TransformerLens this really easy., because if we do another clean run and use a hook to patch in the cached version of an activation, we keep the activation's value the same but delete its computational graph. So we don't at all change the output, but the activation is now a leaf node with no connection to this second run of the network.
A particularly interesting approach here is freezing attention patterns (ie varying the inputs/activations of the model, but holding all attention patterns fixed) - this makes each attention head purely linear, and can help disentangle where interesting computation happens (and because heads are purely linear, attribution patching should work well!)
Patching Multiple Activations
As noted above, attribution patching fails to detect multiple-variable dependence, and plausibly some causal scrubbing esque approach of activation patching in multiple activations containing the key features is necessary to detect this. And this is a genuine weakness of attribution patching! But the above ideas also apply here - if you know all but one of the key variables to patch in, you can patch in those activations in the corrupted run and attribution patching can now detect the single variable depenedence (hopefully!). And once you've figured out the set of activations to patch in, you can apply attribution patching on top of that as a heuristic for what to do next.
The Patching Metric
A crucial and easily overlooked detail in either kind of patching (or attribution in general!) is that of the patching metric you're using. This can completely change your results. My headline take is you should take the logit difference for a binary classification task, and the correct logit/log prob otherwise. Taking the probability can be highly misleading, because it's an exponential function. Model computation is sparse and parallelised, so any single patch is unlikely to recover eg more than 50% of the log prob difference, which is a significant result but can look like almost nothing on probability! My guess is that this is why the ROME paper had to use the extremely coarse patches of sliding windows of 10 attention or MLP layers, rather than being able to dive into eg specific heads or neurons.
I'm also excited to explore calculating the metric from activations rather than purely model logits/log probs. For example, the prefix matching score for induction heads (average attention paid to the appropriate token when given repeated random tokens), the direct logit attribution of a single head, a single neuron's activation, etc. I think this is likely to be an important part of how attribution patching or activation patching is actually useful for reverse-engineering complex circuits in larger models. All prior work looks for end-to-end circuits, but this seems much harder to do directly in eg a 100+ layer model, and I expect that reverse-engineering the features nearer the end, then taking key facts about those as the metric and patching further inwards is likely to give cleaner and easier to interpret information to recover a complex yet sparse circuit. This also feels closer to the image circuit style analysis (eg reverse-engineering curve detecting neurons), though it inherently requires finding something meaningful and interpretable inside the network, which seems hard in a world of polysemanticity and superposition!
Attribution patching breaks more the less linear the function being approximated is, so it in particular benefits from having shallower circuits, and will be less reliable the deeper the circuit is/earlier you are in the model, but crucially how far you are from where the metric is calculated, not inherently from the end.
Broader thoughts:
- I like to take logit diff (= log prob diff) for the final logit for a binary classification task between a clean (correct) and corrupted (incorrect) answer. I discuss why this is so nice in my mech interp explainer
- For tasks of the form "identify a single output token out of many", we could take the probability, log prob or logit
- Taking the probability can be misleading, because it's exponentially weighted - something that recovers 50% of the logit difference could show up as negligible probability change. I recommend against it.
- Logit can be sketchy, since adding 1 to every logit does not change the log probs, so there's no absolute scale. But if comparing similar inputs, it can be basically fine.
- Log prob/prob/logit diff can be sketchy when the corrupted prompt gives the highly confident answer I (incorrect), and we want the highly confident answer C (correct). Because these all have inhibition - high I logit means a lower log prob/prob/logit diff for C, patches pick up on either stuff that breaks I, or stuff that boosts C (and the latter is what we care about, normally)
- For example, patching between
clean_prompt := "The| E|iff|el| Tower| is| located| in| the| city| of" -> " Paris"and the same forcorrupted_prompt := "| Co|los|se|um|" -> " Rome"for logit difference Paris - Rome can be misleading. The residual stream at token position for"el"/"se"and for" Tower"/"um"both matter significantly in early-mid layers, which I speculate is because theis_colosseumfeature and factual recall is computed on the"se"token andis_eiffel_towerfor the Eiffel Tower is on the" Tower"token, (or vice versa), as it's pretty obvious what the nouns are after 3/4 tokens so this is under-determined. Which means that patching from clean to corrupted on" Tower"is moving in Eiffel Tower info, while patching on"se"is breaking Colosseum info- A key factor making things go wrong here is that the model is not using the exact same circuit for Eiffel Tower and Colosseum - it's looking up facts at different positions! - even though it's the same underlying task of factual recall. We got lucky with the IOI example that it didn't have this property!
- For example, patching between
- We could also take the difference between the logit and the average/logsumexp of a "basket" of similar tokens, eg A vs B, C, D on multiple choice, John relative to the top 1000 single token baby names or something, or Paris relative to the first token of capitals of all European countries, etc.
- We can also take something evaluated over many tokens, rather than just the final token, eg the loss (average log prob) on relevant tokens, like on the repeated tokens in an induction-y sequence, or a multi-token name in IOI.
- This can get pretty thorny - given a multi-token name, like
" Ne|el", the model can make an informed guess thatelcomes afterNeeven if it never figured out the correct name, but will be totally stumped ifNeis replaced by another token
- This can get pretty thorny - given a multi-token name, like
Other Variants
There's a lot of other room to vary the core technique of attribution patching! Here's a rough brainstorm of important axes of variation, with notes on how each applies to activation vs attribution patching, and commentary on how to think about them. These are mostly presented in contrast to what I did on the IOI task (many of these have not actually been tried!):
There's a lot of room to vary exactly how you do activation or attribution patching!
- Clean and corrupted prompts
- In the example we had clean + corrupted as two symmetric inputs to the task that differed in one key detail with different answers.
- I generally favour this, but it has issues with controlling for too much, and maybe eliding subtle differences (eg, previous token heads don't show up, and it doesn't change the position of the first two tokens).
- It has the major issue of being laborious to carefully construct the hypothetical, especially since it's really convenient for the token positions to align nicely!
- It can also be hard to distinguish between breaking performance on the corrupted prompt and achieving good performance on the clean prompt!
- The corrupted input could replace the key token (here, S2) with random tokens (either arbitrary tokens, or arbitrary names, etc) or with random noise
- This gives a distribution for corrupted prompts that we can repeatedly sample from, and requires less hand-crafting!
- ROME treats their Gaussian noise as iid normals with 3x the empirical sd of the residual stream there (I think)
- Even that is somewhat hand-crafted, and we could try more automated variants like corrupt each single token and see what happens, or the 5 most recent tokens, everything but the K most recent tokens, etc.
- In the example we had clean + corrupted as two symmetric inputs to the task that differed in one key detail with different answers.
- Patching into clean rather than into corrupted
- Activation patching where a single clean activation is copied into a corrupted prompt is about trying to figure out which activations are sufficient to recover performance. But it totally works the other way round, which is essentially an ablation - we try corrupting activations and see which ones do the most damage.
- Though, it's worth flagging that it can be hard to distinguish between breaking corrupted performance vs boosting clean performance, as discussed in the metrics point.
- Both of these give useful information, and if our end goal is finding a complete circuit, we can think of these as going from from nothing to building up a minimal subgraph (normal patching) vs starting with the entire computational graph and identifying the most important edges to remove (ablation)
- A useful heuristic is thinking through how these interact with multi-variable dependence and redundancy.
- Mutli-variable dependence: Given a function like Boolean AND between feature A and feature B, patching either into corrupted will do nothing, but patching a corrupted version of either will break things!
- Redundancy: Given a function like Boolean OR between feature A and feature B, patching either into corrupted will detect this, but patching a corrupted version of either will do nothing!
- This can also be approximated just as easily with attribution patching!
- Activation patching where a single clean activation is copied into a corrupted prompt is about trying to figure out which activations are sufficient to recover performance. But it totally works the other way round, which is essentially an ablation - we try corrupting activations and see which ones do the most damage.
- Going beyond just two different prompts and eg looking at distributions of clean or corrupted prompts. Mean ablation to the IOI or ABC distribution in the IOI paper is a good start here, and causal scrubbing is another interesting angle. (with names A B A / A B B for the IOI distn, and names A B C for the ABC distribution, so the IOI task is not relevant in the latter)
- Attribution patching is fairly reliant on having a sensible run of the model for the corrupted prompt, though the clean activations can be arbitrary, eg zero ablations, or mean/random ablations to any distribution.
- Distributions are interesting because they can better check how robust your results are, and better disentangle different model properties, eg capturing "the first and third name are equal, but we don't specify what any of the names are".
Related Work
A brief and incomplete overview of prior work that felt reelvant and useful
Activation Patching The earliest work I've seen something like activation patching was Causal Mediation Analysis for Interpreting Neural MLP: The Case of Gender Bias, which studied how different prompts showed gender bias (eg "The nurse washed" -> " her" vs "The doctor washed" -> " his") and how specific model components (layers, heads, etc) mediated this bias, by patching in a different prompt just for that component, or patching in a different prompt for everything but that component. And that work was heavily inspired by Judea Pearl's work on the general study of causal inference. In their work, checking whether a specific head mediates the effect of gender bias consists of taking the clean prompt as the doctor prompt, corrupted as the nurse prompt, and patching for a specific head from clean to corrupted. And the "direct" effect corresponds to patching that head's output from corrupted to clean.
I first came across it as causal tracing in David Bau and Kevin Meng's ROME paper, which heavily inspired this work. I'm not entirely sure where the names activation patching vs causal tracing came from, and they can be used approx interchangeably, but I'll personally focus on using activation patching.
Kevin Wang's Interpretability in the Wild paper significantly refined the technique and created a bunch of variants, like path patching and direct path patching, where the output of one component is just patched in to be to the input to a second component.
Redwood Research's Causal Scrubbing Algorithm is in an extension of the Interpretability in the Wild's work that I think of as activation patching on steroids, though mostly from the perspective of ablations via patching from corrupted into clean. The goal is to be an automated approach to testing whether a specific circuit (subgraph of the model + labels for what features of the input the nodes represent) is actually the cause of a behaviour. The key insight is in thinking of a hypothesis as a set of rules for what properties of the input don't matter for each node, and taking as many patches as we can within the terms of those rules.
Gradient Based Attribution There's a bunch of work on doing attribution of model internals to some metric, including with gradients, of which integrated gradients (explainer summary) is my favourite (it's normally applied to model inputs, but easily transfers to model internals). I haven't come across anything specifically focused on using it to approximate the small, counterfactual changes of patching though!
Attribution The Building Blocks of Interpretability is a notable paper for flexibly applying attribution methods to hidden activations. Prior work looked at hidden activations in order to create spatial saliency maps over the input, but this looked at the actual hidden activations as an end in and of themselves, which is the same spirit as activation patching finds itself.
Future Work
I consider this a somewhat incomplete project that I won't have the time to properly explore, and I'd love to see other people take it up! I generally think that the connections and comparisons to activation patching, and how good it is as an approximation, feel pretty unclear to me, and I'd love to see it applied to a wider setting! I'd also be excited to see it applied to actually search for circuits, both ad-hoc by hand, and as a heuristic for automated search.
My looking for circuits in the wild post outlines a bunch of ideas for concrete problems re looking for circuits in real models, but here's a braindump of things on my short-term to do list for attribution patching
- Induction heads, where we give it repeated random tokens and the metric is loss on the second half of the sequence.
- Try this first on attn-only-2l, but then on a way bigger model (eg GPT-J if you have space) to see how well things hold up.
- Vary the corrupted dataset - if we generate a random sequence of tokens A and the clean prompt is AA, we could try a corrupted prompt of BB, AB, BA, BC, etc - I predict that prompts with one counterfactual (AB or BB or BA) will work much better than the prompt BC which has inherent multi-variable dependence
- Translation - GPT-J has heads that do induction between English, French and German text (as studied in the induction heads paper), can we use attribution patching to rapidly figure out what's going on? It's a large enough model that this is an interesting proof of concept for the technique!
- Continuing the ROME paper's work reverse engineering the factual recall circuit in GPT-2 XL
- Looking for an MLP based circuit, and doing neuron level patching - this is another area where attribution patching shines, since it's such a large search space!
- A cute example would be this hackathon project that found "an neuron" in GPT-2 Large, that was unusually important for predicting whether a or an came next - can you both identify the neuron, and trace back how it was computed?
- Another idea would be trying to reverse engineer a neuron in a toy language model (eg 1 or 2 layers) - attribution patching should work there if it works anywhere for neurons! But it could totally fail, I'm not sure how well it works in practice for neuron stuff.
I'd also be very excited to see work trying to red team attribution patching - finding important false negatives, circuits where it totally breaks compared to other techniques, etc.
I'd also love to see work exploring the variants, especially path patching, and seeing how useful the data actually is and how easy it is to parse to extract the important connections. And ideally seeing how well this can chain into automatically detecting the relevant circuit!
Conclusion
I think activation patching is a really clever and elegant technique, and is a core part of my mech interp toolkit. My hope is that attribution patching can also play a useful supporting role as a heuristic tool in my toolkit, and I've been pleasantly surprised by how easy it is to implement and how well it seems to work in practice. I would also love to get a richer understanding of how well it actually works in practice!
I think there's a lot of potential for this to make the general reasoning and model comparing through counter-factuals much easier and tractable in large models, and hopefully a lot of room for more ambitious variants like using it for path patching.
Acknowledgements
This is a write-up of an incomplete project that I worked on at Anthropic in Feb-March 2022. Thanks a lot to Anthropic as a whole for helping facilitate this work, to Catherine Olsson, Nelson Elhage and Tristan Hume on the then interpretability team, and especially to Chris Olah for helping to spark the idea for this project, suggesting to look at gradient based approximations, and for invaluable mentorship and guidance. I've tried to finish things off since leaving and all remaining mistakes are mine. Thanks also to Chris Olah for discussions that helped greatly improve this post, and to Arthur Conmy for further feedback.